All in One View
Content from Introduction
Last updated on 2026-06-23 | Edit this page
Overview
Questions
- what will the workshop cover?
- how will the workshop work?
- why are open practices important for the humanities?
Objectives
- Understand the goals of the workshop
- Understand workshop expectations
- Identify the role of open practices in the humanities
- Meet Instructors and other participants
Welcome
Before we start the material we will set the stage for the workshop as an environment for learning
Icebreaker
Introduce yourself and your main motivation for learning about open research practices.
Introduction
The following concepts– files, version control, and computational thinking –are your gateway to open research and open tools. We will be teaching these concepts via the following Free Open Source Software (FOSS) tools: bash shell, Git, GitHub and MystMd.
Open Research has a lot of benefits: - free software - Universities typically provide centralized support for using this software (the hardware + people) - independence - transparency
However, because it requires more technical knowledge to use most open software, open research is often focused on the sciences and engineering fields. That said, all areas of scholarship can benefit from more openness.
When was the last time you paid for software or a digital subscription in your work or faced a barrier in a project because you did not have funds for a piece of software?
Goals and Background
This project was funded by ORCA, led by Sarah, Madison, Jeremiah and supported Ayman and Maya.
Our goals for the curriculum and the workshop are: - platform independence - more collaboration
Outline
By the end of this workshop you will have created an interactive article using Myst.
The workshop is split over four parts, each planned for roughly one half day. In the first part we will set the stage, focusing on some higher level concepts and basic terminology. We will make your very first (or not?) small open source projects. Finally, we will do the installation steps of the software required for the rest of the parts. The downside to open source is that it can be hard to start with because it assumes the user knows more than commercial software does. By the end of the workshop, you will have a better handle on these basics, but to start, we will use some time together to run installs so that you can get help. You will also have a tiny bit of “homework” to find some files and content of your own to use in later sessions, you can probably do this while your installs run.
The next two sessions, we will learn about the bash
shell and git. We will learn the shell for two reasons: 1)
it is a good way to get hands on practice with most of the key concepts
in open source (really, computers broadly) and 2) a lot of open source
software is only distributed with a command line interface (CLI; read as
an abbreviation) instead of a graphical user interface (GUI, pronounced
“gooey”). Git is a version control software that is the current
foundation of open source. Most projects are managed with git. GitHub is
a popular host for git, owned by Microsoft. There are other hosts though
and you could even run your own, git is also open source! We will use
GitHub, but the skills you learn in this workshop will be
transferable.
On the final day, we will bring these concepts together building your
own article with Myst. This will be a way to practice, tying all of the
concepts together. We will host your article on GitHub, manage it using
git via bash, and build it with
mystmd.
- This will be a hands on workshop
Content from Jargon Busting
Last updated on 2026-06-23 | Edit this page
Overview
Questions
- What terms, phrases, or ideas around code or software development have you come across and feel you should know better?
Objectives
- Explain terms, phrases, and concepts associated with open research.
- Compare knowledge of these terms, phrases, and concepts.
- Differentiate between these terms, phrases, and concepts.
Jargon Busting!
This exercise is an opportunity to gain a firmer grasp on the concepts around data, code or software development in the humanities’ world.
- Pair with a neighbor and decide who will take notes (or depending on the amount of time available for the exercise, skip to forming groups of four to six).
- Talk for three minutes (your instructor will be timing you!) on any terms, phrases, or ideas around code or software development related to open research, open source, or even computing in general that you’ve come across and perhaps feel you should know better.
- Next, get into groups of four to six.
- Make a list of all the problematic terms, phrases, and ideas each pair came up with. Retain duplicates.
- Identify common words as a starting point - spend 10 minutes working together to try to explain what the terms, phrases, or ideas on your list mean. Note: use both each other and the internet as a resource.
- Identify the terms your groups were able to explain as well as those you are still struggling with.
- Each group then reports back on one issue resolved by their group and one issue not resolved by their group.
- The instructor will collate these on a whiteboard and facilitate a discussion about what we will cover in the workshop and where you can go for help on those things we won’t cover. Any jargon or terms that will not be covered specifically are good notes.
Busting Tips
Often, workshop attendees ask if there is a handout of common terms and definitions as there is not enough time to explain all the terms in a jargon busting exercise. Many of the terms are covered in our lessons such as open source, version control, terminal, git… but with so much variation between our jargon busting sessions, it is difficult to create a common handout. You can start with resources such as TechTerms or the Data Thesaurus but you may also need to use the internet to explain terms. The Sideways Dictionary is another great place to get examples of jargon explained in plain English.
Keep in mind that our goal is not to explain all the terms we list out in the exercise, but instead to highlight how much jargon we use in our daily work and to come up with a shared understanding for a select number of jargon terms.
If you do have a helpful handout that you would like to share, please submit an issue/pull request to this lesson.
- It helps to share what you know and don’t know about open research and open software jargon.
Content from Hello Open Source
Last updated on 2026-06-23 | Edit this page
Overview
Questions
- What is open source?
- What is GitHub Pages?
- How can I use GitHub Pages to collaborate and share my work?
Objectives
- Create a GitHub repo
- Complete the steps to make a commit
- Differentiate Markdown and HTML
- Differentiate source and rendered content
- Identify the parts of the GitHub Interface
- Create a Website using GitHub Pages default settings
- Share the link to your webpage with a partner and confirm they can view it
- Consider what options there are to collaborate on a website or contribute to someone else’s webpage
What is open source
Open source is when a software or a project is published online and available to the public to view the details of or contribute to.
Let’s use an example of our own to see what it’s like to have an open source project.
GitHub
GitHub is a developer platform that allows developers to create and hold projects on it. It is benificial for reasons such as managing different versions of a project, collaboration and task management.
GitHub Pages
GitHub Pages is a simple service to publish a website directly on
GitHub from a Git repository. You can add some files and folders to a
repository and GitHub Pages turns it into a website. There are multiple
ways of doing so, either by having GitHub use an HTML file
(index.html) directly to publish, or by using a tool that
GitHub provides called Jekyll which renders Markdown into HTML. You can
use the contents of one md file directly named either
README.md or `index.md and Jekyll will render them into a
webpage making it really easy to setup a blog or a template-based
website. You can then configure Jekyll with more detailed configuration
settings to make your webpage more customized. There are many tools to
convert markdown (or other simple formats, like RestructuredText) to
HTML, called static site
generators. We will see another one later, called Mystmd (read myst
Markdown). In this case the markdown is called the source and
the HTML is the rendered output. One way to think about source
is that it is all of the contents you need to get to the output, but in
an easier to modify form. The rendered output is what we want to share
with our users, here readers, but the source is easier to manage. The
static site generator, combines everything. This makes it so that
content that should appear for example on every page does not need to be
repeated. It also allows us to separate the content from the visual
style for the most part.
These are static sites because other tools, for example wordpress, also separate the content and the style, but they do so dynamically, when a visitor goes to the website, it pulls content from a database, inserts it into the html and then sends it to the visitor’s browser. ### Why GitHub Pages is awesome!
GitHub Pages provides an easy way to publish your material mostly for
free with easy means to modify it and format it with a nice theme of
your preference. It also comes with all the collaboration and version
control features that Git and GitHub provide us with.
Version control features can be very useful for academic citations. Most
people have had the experience of following up a reference to a website
and either getting a 404 error or seeing something completely different.
Although using versions on your site doesn’t guarantee this won’t
happen, it does make it easier to manage old versions of your site. More
on that later.
Creating a new repository
A repository can be thought of in many ways, you can think of it as a big folder that holds all the files of your project, or like a vessel that contains all the data and meta-data of your project. Overall a repository is an entity that represents one full project.
To create a new repo login to your GitHub account. At the top, right
corner click on the + sign and choose
New repository
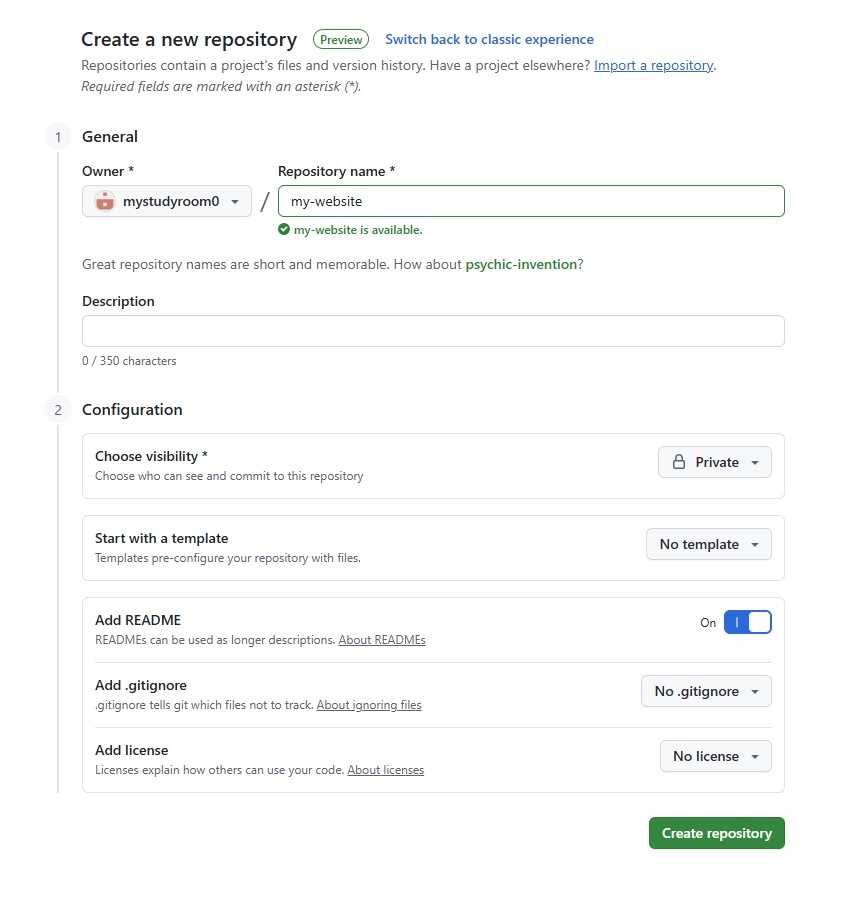
Give your repository a meaningful name that suits the contents it
shall hold. And we encourage adding something to the optional
description section. Toggle the Add a README file button
and click on the green Create Repository button.
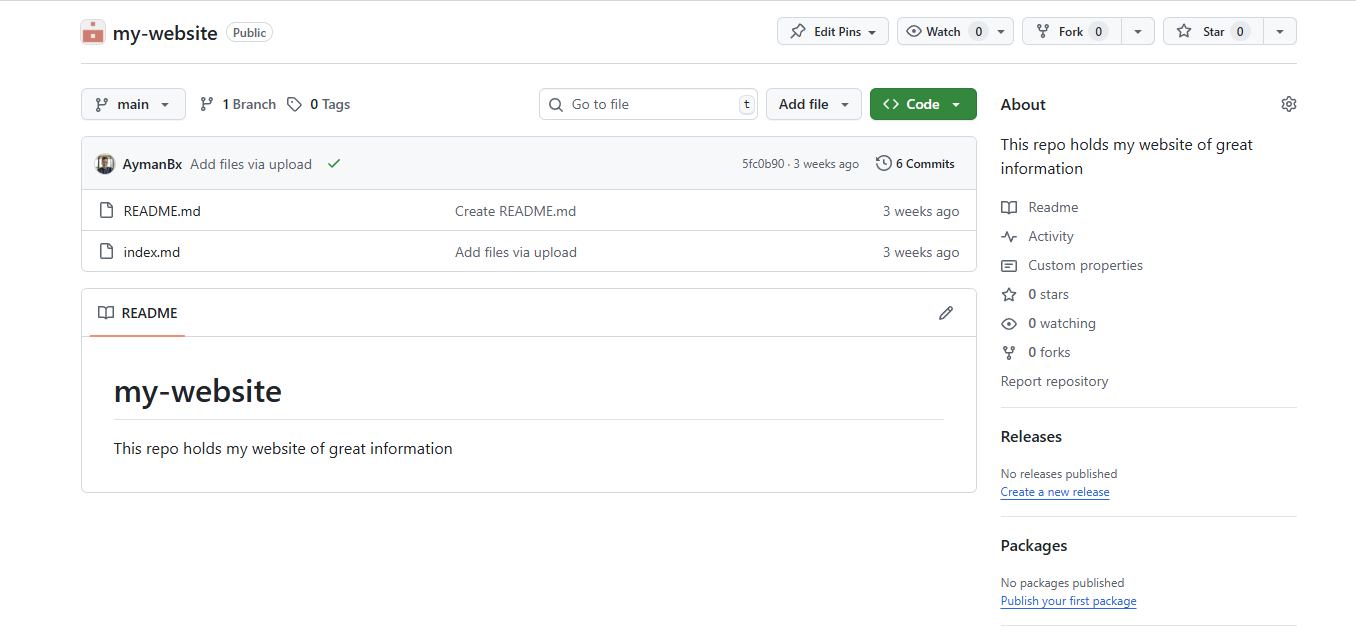
Here is a preview of how the new repo would look like:
Enable GitHub Pages
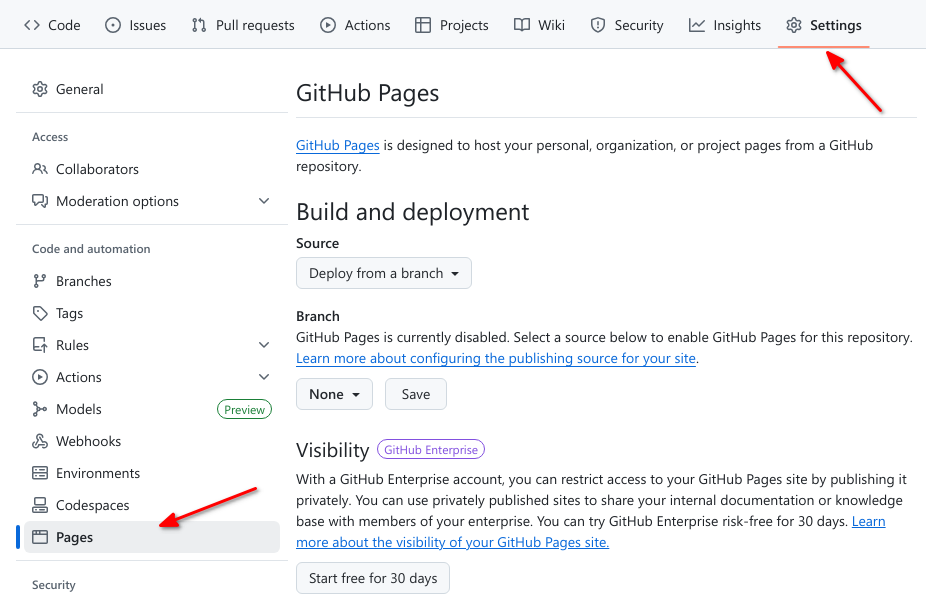
GitHub Pages is turned off by default for all new repositories, and can be turned on in the settings menu for any repository.
Let’s set up a new site by enabling GitHub Pages for our project.
Go to the Pages section of your repository’s Settings:
Source branch (required)
Pages needs to know the branch in your repository from which you want
to serve your site. This can be any branch, including
main.
Select then save the source branch:
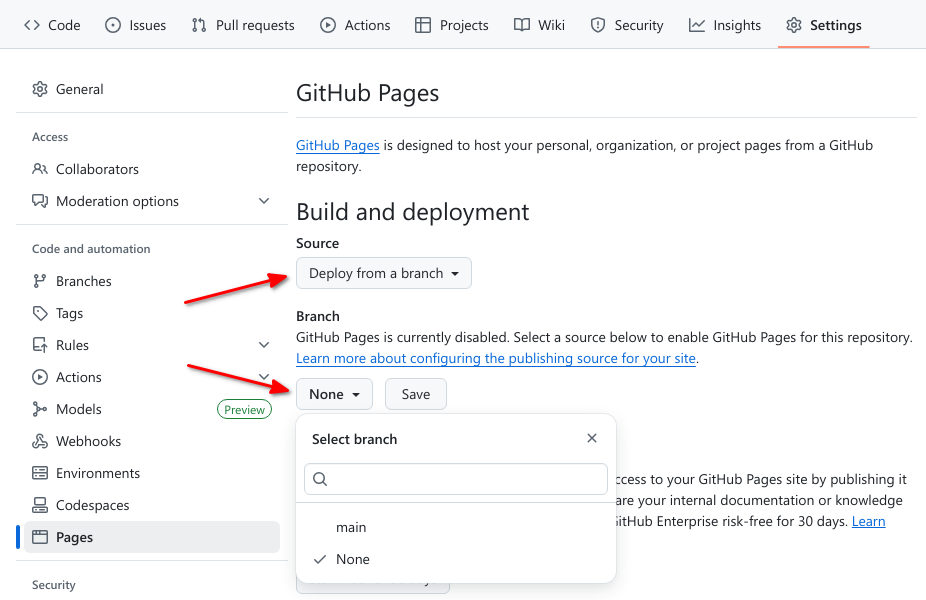
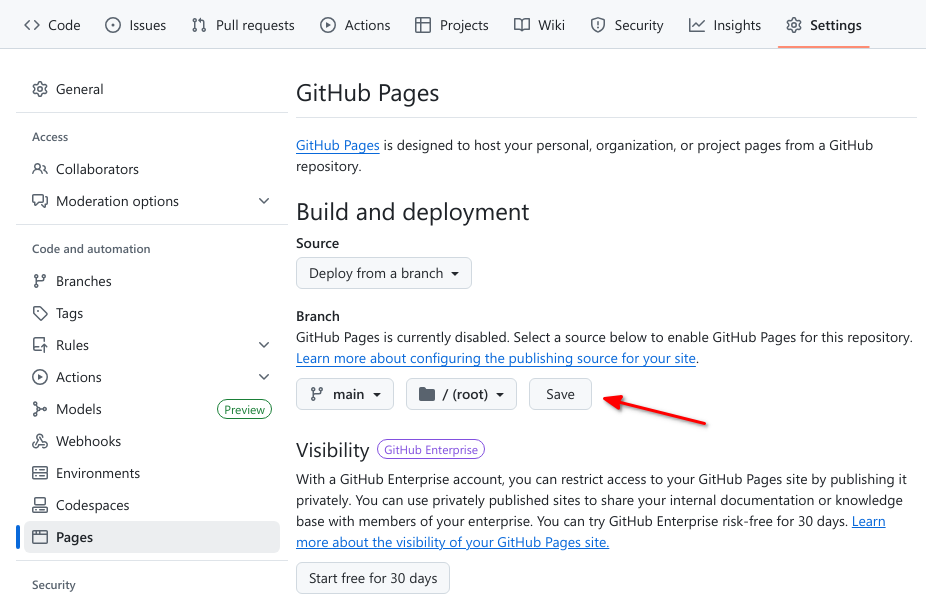
Theme (optional)
GitHub Pages provides different themes to visually style and organize your site’s content. Choosing a theme is optional, and themes can be interchanged quickly.
See the GitHub Pages documentation for further information on using themes.
View your site
If we now visit
https://mystudyroom0.github.io/my-website/, we should see
the contents of the index.md file that created earlier. Usually it’s
available instantly, but it can take a few seconds and in the worst case
a few minutes if GitHub are very busy.
And here’s a preview of the new website

Here, my repository was owned by an GitHub organization (or group)
named mystudyroom0, hence the name in the link. The
repository is named my-website, hence the header of the
page. And the content was what I had typed inside my README
file which in this case was rendered to be the content of the
webpage.
Challenge: View your own webpage:
See if you can find the link to your newly generated webpage and share it on eitherpad. Add the link to your webpage to the about section of your repository.
Remember where in the settings we enabled GitHub Pages, the link should be right there.
To update your repo’s about to add the link to your webpage you can
find the about section in the right hand side of the main page of your
repo. 
Click on the gear button and paste the link in the website box.

Adding new content to your webpage
Find a text file of an article of yours or a one page paper that you would want to see used as the content of your new webpage.
On your repository code<> page click
Upload files from the Add file dropdown
menu

Drag your file and drop it in the following page and select
Commit changes

A commit is an annotated change or a checkpoint in a repository. We shall talk more about it later on.
After successfully uploading the file it can be found in the list of
files of your repo. Click on it to open it and then click on the edit
button on the top of the file.
Rename the file to index.md then commit the changes
again.

Notice the “commit message” automatically generated by GitHub regarding this change.
Wait a minute for the new changes to render and then view your website again

Challenge: Contributing to a page owned by someone else
To practice open source, GitHub and Markdown we can contribute to a GitHub pages site. Pair up in groups of two (or more if needed) and do the exercises below together.
Go to https://github.com/some-humanist/my-website, where “some-humanist” is the username of your exercise partner.
Find the website link in their about section of their repo and open it.
Scroll to the bottom of their webpage and find the button that says
improve this page.Click on
Fork this repository. This takes you to a file editor that edits your partner’s article.Now is good chance to try some Markdown syntax. Try some of the examples at Mastering Markdown. You can preview how it will look before you commit changes.
Once you are ready to commit, enter a short commit message, select “Create a new branch for this commit and start a pull request” and press “Propose changes” to avoid commiting directly to the main branch.
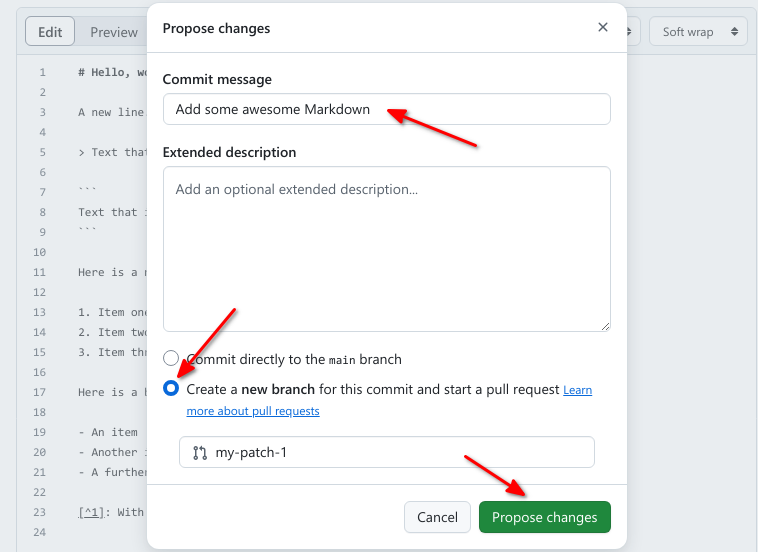
You can now go to the repository on your account and click “New Pull Request” button, where you can select base branches repositories, review the changes and add an additional explanation before sending the pull request (this is especially useful if you make a single pull request for multiple commits).
Your partner should now see a pull request under the “Pull requests” tab and can accept (“Merge pull request”) the changes there. Try this.
This whole process of making a fork and a pull request might seem a bit cumbersome. Try to think of why it was needed? And why it’s called “pull request”?
We made a fork and a pull request because we did not have permission to edit (or commit) the repository directly. A fork is a copy of the repository that we can edit. By making a pull request we ask the owner of the repository if they would like to accept (pull in) the changes from our fork (our copy) into their version. The owner can then review the changes and choose to accept or reject them.
A fork is a copy of someone else’s project that is owned by you!
A pull request is a proposal from you to the owner or lead of a project to make some changes to it. More on PRs later.
You can open pull requests on any repository you find on GitHub. If you are a group of people who plan to collaborate closely, on the other hand, it’s more practical to grant everyone access to commit directly instead.
Optional challenge: Adding an HTML page
GitHub Pages is not limited to Markdown. If you know some HTML, try adding an HTML page to your repository. You could do this on the command line or directly on GitHub. The steps below are for working directly on GitHub:
- To add a new file directly on GitHub, press the “Create new file” button.
Name it ‘test.html’, add some HTML and click “Commit new file”.
Try opening
https://some-humanist.github.io/hello-world/test(replace “some-humanist” with your username). Notice that the HTML extension is not included.
- When editing fils in GitHub.com, we have to commit to save changes
- A commit is a snapshot that we can go back to
- Markup languages use special formatting to label the content and indicate styling in addition to the content in the file, examples include Markdown, ReStructured Text (out of scope), XML, and HTML
- Markdown is a a style of markup that is human and machine readable, it is rendered as HTML
- HTML is the formt of markup that web browsers use
- Source content is what we edit and may content developer information, rendered content (or built) is what is for the reader, output by a build process
- GitHub Pages offer a free host for a website that is rendered from simple text
- Collaboration and version control rules and workflows can be used with GitHub Pages as we shall see in future episodes
Content from Getting Ready for the Next step
Last updated on 2026-06-23 | Edit this page
Overview
Questions
- what tools will we use in this workshop?
Objectives
- install software needed for the rest of the workshop
Challenge
Go to the setup page and follow instructions to install. Use sticky notes to indicate if you need help.
Confirm your setup
Check that you know how to open a terminal window
Confirm all of the following commands work in your terminal -
myst --version - git --version
Homework
We will work with both example data and give you time to work with your own files. To facilitate that, take a few minutes over the next couple of days to a body of text that you can work with on the last day of the workshop.
Closing
Reflection
Take a few minutes and make notes for yourself about the most important things you want to remember from today. Think about these as what would you want to review in a few minutes before the next session starts.
Some guiding questions:
- What was most surprising?
- Did anything challenge what you thought before?
- Do you have new ideas about how you might approach an aspect of your work?
Feedback
Use your sticky notes to give the instructors feedback for today.
- On the “good” color, share one thing you liked about today or something you are glad you learned.
- On the “need help” color, share one thing you are still confused about or one thing that could have been better
- git is an open source version control system
- bash is an open source shell program (interpreter to chat with)
- myst is a program the builds markdown to html and javascript
Content from What is the shell?
Last updated on 2026-06-23 | Edit this page
Overview
Questions
- What is the shell?
- What is the command line?
- Why should I use it?
Objectives
- Describe the basics of the Unix shell
- Explain why and how to use the command line
Introduction: What is the shell, and why should I use it?
If you’ve ever had to deal with large amounts of data or large numbers of digital files scattered across your computer or a remote server, you know that copying, moving, renaming, counting, searching through, or otherwise processing those files manually can be immensely time-consuming and error-prone. Fortunately, there is an extraordinarily powerful and flexible tool designed for just that purpose.
The shell (sometimes referred to as the “Unix shell”, for the operating system where it was first developed) is a program that allows you to interact with your computer using typed text commands. It is the primary interface used on systems like macOS, as well as other Linux and Unix-based systems. The shell can also be installed optionally on other operating systems such as windows.
What is Unix?
Unix is an operating system (OS) developed in 1969, which laid the groundwork for other OSs. This system has a few key features for users, like the shell for communication.
What is Linux?
Linux is an open-source operating system similar to Unix, but developed later. The shell is also used in this operating system for the same communication purposes.
It is the definitive example of a “command line interface”, where instructions are given to the computer by typing in commands, and the computer responds by performing a task or generating an output. This output is often directed to the screen, but can be directed to a file, or even to other commands, creating powerful chains of actions with very little effort.
Using a shell sometimes feels more like programming than like using a mouse. Commands are terse (often only a couple of characters long), their names are frequently cryptic, and their output is lines of text rather than something visual like a graph. On the other hand, with only a few keystrokes, the shell allows you to combine existing tools into powerful pipelines and to handle large volumes of data automatically. This automation not only makes you more productive, but also improves the reproducibility of your workflows by allowing you to save and then repeat them with a few simple commands. Understanding the basics of the shell provides a useful foundation for learning to program, since some of the concepts you will learn here—such as loops, values, and variables—will translate to programming.
The shell is one of the most productive programming environments ever created. Once mastered, you can use it to experiment with different commands interactively, then use what you have learned to automate your work.
In this session we will introduce task automation by looking at how data can be manipulated, counted, and mined using the shell. The session will cover a small number of basic commands, which will constitute building blocks upon which more complex commands can be constructed to fit your data or project. Even if you do not do your own programming or your work currently does not involve the command line, knowing some basics about the shell can be useful.
Note to Lesson Instructor: Consider providing an example here of how you’ve used the Unix shell to solve a problem in the last week or month
Where is my shell?
The shell is a program that is usually launched on your computer much in the way you would start any other program. However, there are numerous kinds of shells with different names, which may or may not be already installed. The shell is central to Linux-based computers, and macOS machines ship with Terminal, a shell program. For Windows users, popular shells such as Cygwin or Git Bash provide a Unix-like interface, but may need to be installed separately. In Windows 10, the Windows Subsystem for Linux also gives access to a Bash shell command-line tool.
For this lesson, we will use Git Bash for Windows users, Terminal for macOS, and the shell for Linux users.
- The shell is powerful
- The shell can be used to copy, move, and combine multiple files
Content from Working with files and directories
Last updated on 2026-06-23 | Edit this page
Overview
Questions
- How can I copy, move, and delete files and directories?
- How can I read files?
Objectives
- Work with files and directories from the command line
- Use tab completion to limit typing
- Use commands to print and view files and parts of files
- Use commands to move/rename, copy, and delete files
Working with files and folders
As well as navigating directories, we can interact with files on the command line: we can read them, open them, run them, and even edit them. In fact, there’s really no limit to what we can do in the shell, but even experienced shell users still switch to graphical user interfaces (GUIs) for many tasks, such as editing formatted text documents (Word or OpenOffice), browsing the web, editing images, etc. But if we wanted to make the same crop on hundreds of images, say, the pages of a scanned book, then we could automate that cropping work by using shell commands.
What is a Graphical User Interface (GUI)?
A breakdown of this term: “Graphical”– contains elements you can click on, “User”– suited for people to use, “Interface”– the platform you are working with. Essentially, this is an electronic platform that is designed with buttons and other clickable features, as opposed to an interface that requires text. This would be a different user-computer interaction approach than using a shell.
Before getting started, we will use ls to list the
contents of our current directory. Using ls periodically to
view your options is useful to orient oneself.
OUTPUT
Applications Documents Library Music Public
Desktop Downloads Movies PicturesWe will try a few basic ways to interact with files. Let’s first move
into the shell-lesson directory on your desktop.
OUTPUT
/Users/humanist/Desktop/shell-lessonHere, we will create a new directory and move into it:
Here we used the mkdir command (meaning ‘make
directories’) to create a directory named ‘firstdir’. Then we moved into
that directory using the cd command.
But wait! There’s a trick to make things a bit quicker. Let’s go up one directory.
Instead of typing cd firstdir, let’s try to type
cd f and then press the Tab key. We notice that the shell
completes the line to cd firstdir/.
Tab for Auto-complete
Pressing tab at any time within the shell will prompt it to attempt to auto-complete the line based on the files or sub-directories in the current directory. Where two or more files have the same characters, the auto-complete will only fill up to the first point of difference, after which we can add more characters, and try using tab again. We would encourage using this method throughout today to see how it behaves (as it saves loads of time and effort!).
With Desktop, Documents, and
Downloads folders living in the same directory. Let’s say
we want to change directory into the Downloads folder while
using the Tab auto-complete help.
If we press Tab at this point we can’t really
auto-complete because there are three different folders that start with
the letter D. If we double press Tab the shell
provides us with the options that start with the letter
D
OUTPUT
Desktop Documents
DownloadsLet’s try again
With double press on Tab we get
OUTPUT
Documents Downloads Finally if we try the auto-complete method with enough unique set of
characters that identify the word Downloads bash can auto
complete the word:
Tab The shell will auto complete your command:
This feature can be very helpful for quicker access to files and folders with known names. It can also prevent typos, which is especially helpful in files with long names.
Reading files
If you are in firstdir, use cd .. to get
back to the shell-lesson directory.
Here there are copies of two public domain books downloaded from Project Gutenberg along with other files we will cover later.
OUTPUT
total 33M
-rw-rw-r-- 1 humanist staff 383K Feb 22 2017 201403160_01_text.json
-rw-r--r-- 1 humanist staff 3.6M Jan 31 2017 2014-01-31_JA-africa.tsv
-rw-r--r-- 1 humanist staff 7.4M Jan 31 2017 2014-01-31_JA-america.tsv
-rw-rw-r-- 1 humanist staff 125M Jun 10 2015 2014-01_JA.tsv
-rw-r--r-- 1 humanist staff 1.4M Jan 31 2017 2014-02-02_JA-britain.tsv
-rw-r--r-- 1 humanist staff 582K Feb 2 2017 33504-0.txt
-rw-r--r-- 1 humanist staff 598K Jan 31 2017 829-0.txt
-rw-rw-r-- 1 humanist staff 18K Feb 22 2017 diary.html
drwxr-xr-x 1 humanist staff 64B Feb 22 2017 firstdirThe files 829-0.txt and 33504-0.txt holds
the content of book #829 and #33504 on Project Gutenberg. But we’ve
forgot which books, so we try the cat command to
read the text of the first file:
The terminal window erupts and the whole book cascades by (it is printed to your terminal), leaving us with a new prompt and the last few lines of the book above this prompt.
Often we just want a quick glimpse of the first or the last part of a
file to get an idea about what the file is about. To let us do that, the
Unix shell provides us with the commands head and
tail.
OUTPUT
The Project Gutenberg eBook, Gulliver's Travels, by Jonathan Swift
This eBook is for the use of anyone anywhere at no cost and with
almost no restrictions whatsoever. You may copy it, give it away or
re-use it under the terms of the Project Gutenberg License included
with this eBook or online at www.gutenberg.orgThis provides a view of the first ten lines, whereas
tail 829-0.txt provides a perspective on the last ten
lines:
OUTPUT
Most people start at our Web site which has the main PG search facility:
http://www.gutenberg.org
This Web site includes information about Project Gutenberg-tm,
including how to make donations to the Project Gutenberg Literary
Archive Foundation, how to help produce our new eBooks, and how to
subscribe to our email newsletter to hear about new eBooks.If ten lines is not enough (or too much), we would check
man head to see if there exists an option to specify the
number of lines to get (there is: head -n 20 will print 20
lines).
Another way to navigate files is to view the contents one screen at a
time. Type less 829-0.txt to see the first screen,
spacebar to see the next screen and so on, then
q to quit (return to the command prompt).
Like many other shell commands, the commands cat,
head, tail and less can take any
number of arguments (they can work with any number of files). We will
see how we can get the first lines of several files at once. To save
some typing, we introduce a very useful trick first.
Re-using commands
On a blank command prompt, press the up arrow key and notice that the previous command you typed appears before your cursor. We can continue pressing the up arrow to cycle through your previous commands. The down arrow cycles back toward your most recent command. This is another important labour-saving function and something we’ll use a lot.
Press the up arrow until you get to the head 829-0.txt
command. Add a space and then 33504-0.txt (Remember your
friend Tab? Type 3 followed by tab to get
33504-0.txt), to produce the following command:
OUTPUT
==> 829-0.txt <==
The Project Gutenberg eBook, Gulliver's Travels, by Jonathan Swift
This eBook is for the use of anyone anywhere at no cost and with
almost no restrictions whatsoever. You may copy it, give it away or
re-use it under the terms of the Project Gutenberg License included
with this eBook or online at www.gutenberg.org
==> 33504-0.txt <==
The Project Gutenberg EBook of Opticks, by Isaac Newton
This eBook is for the use of anyone anywhere at no cost and with
almost no restrictions whatsoever. You may copy it, give it away or
re-use it under the terms of the Project Gutenberg License included
with this eBook or online at www.gutenberg.org
Title: Opticks
or, a Treatise of the Reflections, Refractions, Inflections,All good so far, but if we had lots of books, it would be
tedious to enter all the filenames. Luckily the shell supports
wildcards! The ? (matches exactly one character) and
* (matches zero or more characters) are probably familiar
from library search systems. We can use the * wildcard to
write the above head command in a more compact way:
More on wildcards
Wildcards are a feature of the shell and will therefore work with
any command. The shell will expand wildcards to a list of files
and/or directories before the command is executed, and the command will
never see the wildcards. As an exception, if a wildcard expression does
not match any file, Bash will pass the expression as a parameter to the
command as it is. For example typing ls *.pdf results in an
error message that there is no file called *.pdf.
Moving, copying and deleting files
We may also want to change the file name to something more
descriptive. We can move it to a new name by using the
mv or move command, giving it the old name as the first
argument and the new name as the second argument:
This is equivalent to the ‘rename file’ function.
Afterwards, when we perform a ls command, we will see
that it is now called gulliver.txt:
OUTPUT
2014-01-31_JA-africa.tsv 2014-02-02_JA-britain.tsv gulliver.txt
2014-01-31_JA-america.tsv 33504-0.txt
2014-01_JA.tsvCopying a file
Instead of moving a file, you might want to copy a
file (make a duplicate), for instance to make a backup before modifying
a file. Just like the mv command, the cp
command takes two arguments: the old name and the new name. How would
you make a copy of the file gulliver.txt called
gulliver-backup.txt? Try it!
Renaming a directory
Renaming a directory works in the same way as renaming a file. Try
using the mv command to rename the firstdir
directory to backup.
Moving a file into a directory
If the last argument you give to the mv command is a
directory, not a file, the file given in the first argument will be
moved to that directory. Try using the mv command to move
the file gulliver-backup.txt into the backup
folder.
The wildcards and regular expressions
The ? wildcard matches one character. The *
wildcard matches zero or more characters. If you attended the lesson on
regular expressions, do you remember how you would express that as
regular expressions?
(Regular expressions are not a feature of the shell, but some commands support them. We’ll get back to that.)
- The
?wildcard matches the regular expression.(a dot) - The
*wildcard matches the regular expression.*
Using history
Use the history command to see a list of all the
commands you’ve entered during the current session. You can also use
Ctrl + r to do a reverse lookup. Press
Ctrl + r, then start typing any part of the
command you’re looking for. The past command will autocomplete. Press
enter to run the command again, or press the arrow keys to
start editing the command. If multiple past commands contain the text
you input, you can Ctrl + r repeatedly to cycle
through them. If you can’t find what you’re looking for in the reverse
lookup, use Ctrl + c to return to the prompt. If
you want to save your history, maybe to extract some commands from which
to build a script later on, you can do that with
history > history.txt. This will output all history to a
text file called history.txt that you can later edit. To
recall a command from history, enter history. Note the
command number, e.g. 2045. Recall the command by entering
!2045. This will execute the command.
Using the echo command
The echo command simply prints out a text you specify.
Try it out: echo 'Library Carpentry is awesome!'.
Interesting, isn’t it?
You can also specify a variable. First type NAME=
followed by your name, and press enter. Then type
echo "$NAME is a fantastic library carpentry student" and
press enter. What happens?
You can combine both text and normal shell commands using
echo, for example the pwd command you have
learned earlier today. You do this by enclosing a shell command in
$( and ), for instance $(pwd).
Now, try out the following:
echo "Finally, it is nice and sunny on" $(date). Note that
the output of the date command is printed together with the
text you specified. You can try the same with some of the other commands
you have learned so far.
Why do you think the echo command is actually quite important in the shell environment?
You may think there is not much value in such a basic command like
echo. However, from the moment you start writing automated
shell scripts, it becomes very useful. For instance, you often need to
output text to the screen, such as the current status of a script.
Moreover, you just used a shell variable for the first time, which can be used to temporarily store information, that you can reuse later on. It will give many opportunities from the moment you start writing automated scripts.
Finally, onto deleting. We won’t use it now, but if you do want to
delete a file, for whatever reason, the command is rm, or
remove.
Using wildcards, we can even delete lots of files. And adding the
-r flag we can delete folders with all their content.
Unlike deleting from within our graphical user interface,
there is no warning, no recycling bin from which you
can get the files back and no other undo options! For that
reason, please be very careful with rm and extremely
careful with rm -r.
- The shell can be used to copy, move, and combine multiple files
Content from Automating the tedious with loops
Last updated on 2026-06-23 | Edit this page
Overview
Questions
- What is a loop?
- How can a loop be used to repeat a task?
Objectives
- Describe how loops can be used to repeat tasks
- Implement a loop to rename several files
Writing a Loop
Loops are key to productivity improvements through
automation as they allow us to execute commands repetitively. Similar to
wildcards and tab completion, using loops also reduces the amount of
typing (and typing mistakes). Suppose we have several hundred document
files named project_1825.txt,
project_1863.txt, XML_project.txt and so on.
We would like to change these files, but also save a version of the
original files, naming the copies backup_project_1825.txt
and so on.
We can use a loop to do that. Here’s a simple example that creates a backup copy of four text files in turn.
Let’s first create those files:
$ touch a.txt b.txt c.txt d.txtThis will create four empty files with those names.
Now we will use a loop to create a backup version of those files. First let’s look at the general form of a loop:
BASH
for thing in list_of_things
do
operation_using $thing # Indentation within the loop is not required, but aids legibility
doneWe can apply this to our example like this:
OUTPUT
a.txt
b.txt
c.txt
d.txtWhen the shell sees the keyword for, it knows to repeat
a command (or group of commands) once for each thing in a
list. For each iteration, the name of each thing is sequentially
assigned to the loop variable. The commands inside the
loop are executed before moving on to the next thing in the list. Inside
the loop, we call for the variable’s value by putting $ in
front of it. The $ tells the shell interpreter to treat the
variable as a variable name and substitute its value in
its place, rather than treat it as text or an external command.
Double-quoting variable substitutions
Because real-world filenames often contain white-spaces, we wrap
$filename in double quotes ("). If we didn’t,
the shell would treat the white-space within a filename as a separator
between two different filenames, which usually results in errors.
Therefore, it’s best and generally safer to use "$..."
unless you are absolutely sure that no elements with white-space can
ever enter your loop variable (such as in episode 9).
In this example, the list is four filenames: ‘a.txt’, ‘b.txt’,
‘c.txt’, and ‘d.txt’. Each time the loop iterates, it will assign a file
name to the variable filename and run the cp
command. The first time through the loop, $filename is
a.txt. The interpreter prints the filename to the screen
and then runs the command cp on a.txt,
(because we asked it to echo each filename as it works its way through
the loop). For the second iteration, $filename becomes
b.txt. This time, the shell prints the filename
b.txt to the screen, then runs cp on
b.txt. The loop performs the same operations for
c.txt and then for d.txt and then, since the
list only included these four items, the shell exits the
for loop at that point.
Follow the Prompt
The shell prompt changes from $ to > and
back again as we were typing in our loop. The second prompt,
>, is different to remind us that we haven’t finished
typing a complete command yet. A semicolon, ;, can be used
to separate two commands written on a single line.
Same Symbols, Different Meanings
Here we see > being used as a shell prompt, but
> can also be used to redirect output from a command
(i.e. send it somewhere else, such as to a file, instead of displaying
the output in the terminal) — we’ll use redirection in episode 9. Similarly, $
is used as a shell prompt, but, as we saw earlier, it is also used to
ask the shell to get the value of a variable.
If the shell prints > or $ then
it expects you to type something, and the symbol is a prompt.
If you type > in the shell, it is an
instruction from you to the shell to redirect output.
If you type $ in the shell, it is an
instruction from you to the shell to get the value of a variable.
We have called the variable in this loop filename in
order to make its purpose clearer to human readers. The shell itself
doesn’t care what the variable is called.
This is our first look at loops. We will run another loop in the Counting and Mining with the Shell episode.

Running the loop from a Bash script
Alternatively, rather than running the loop above on the command
line, you can save it in a script file and run it from the command line
without having to rewrite the loop again. This is what is called a Bash
script which is a plain text file that contains a series of commands
like the loop you created above. In the example script below, the first
line of the file contains what is called a Shebang (#!)
followed by the path to the interpreter (or program) that will run the
rest of the lines in the file (/bin/bash). The second line
demonstrates how comments are made in scripts. This provides you with
more information about what the script does. The remaining lines contain
the loop you created above. You can create this file in the same
directory you’ve been using for the lesson and by using the text editor
of your choice (e.g. nano) but when you save the file, make sure it has
the extension .sh
(e.g. my_first_bash_script.sh). When you’ve done this, you
can run the Bash script by typing the command bash and the file name via
the command line (e.g. bash my_first_bash_script.sh).
#!/bin/bash
# This script loops through .txt files, returns the file name, first line, and last line of the file
for file in *.txt
do
echo $file
head -n 1 $file
tail -n 1 $file
doneDownload/copy my_first_bash_script.sh. For more on Bash scripts, see Bash Scripting Tutorial - Ryans Tutorials.
- Looping is the foundation for working smarter with the command line
- Loops help us to do the same (or similar) things to a bunch of items
Content from Counting and mining with the shell
Last updated on 2026-06-23 | Edit this page
Overview
Questions
- How can I count data?
- How can I find data within files?
- How can I combine existing commands to do new things?
Objectives
- Demonstrate counting lines, words, and characters with the shell command wc and appropriate flags
- Use strings to mine files and extract matched lines with the shell
- Create complex single line commands by combining shell commands and regular expressions to mine files
- Redirect a command’s output to a file.
- Process a file instead of keyboard input using redirection.
- Construct command pipelines with two or more stages.
- Explain Unix’s ‘small pieces, loosely joined’ philosophy.
Counting and mining data
Now that you know how to navigate the shell, we will move onto learning how to count and mine data using a few of the standard shell commands. While these commands are unlikely to revolutionise your work by themselves, they’re very versatile and will add to your foundation for working in the shell and for learning to code. The commands also replicate the sorts of uses library users might make of library data.
Counting and sorting
We will begin by counting the contents of files using the Unix shell. We can use the Unix shell to quickly generate counts from across files, something that is tricky to achieve using the graphical user interfaces of standard office suites.
Let’s start by navigating to the directory that contains our data
using the cd command:
Remember, if at any time you are not sure where you are in your
directory structure, use the pwd command to find out:
OUTPUT
/Users/humanist/Desktop/shell-lessonAnd let’s check what files are in the directory and how large they
are with ls -lhS:
OUTPUT
total 139M
-rw-rw-r-- 1 humanist staff 126M Jun 10 2015 2014-01_JA.tsv
-rw-r--r-- 1 humanist staff 7.4M Jan 31 18:47 2014-01-31_JA-america.tsv
-rw-r--r-- 1 humanist staff 3.6M Jan 31 18:47 2014-01-31_JA-africa.tsv
-rw-r--r-- 1 humanist staff 1.4M Jan 31 18:47 2014-02-02_JA-britain.tsv
-rw-r--r-- 1 humanist staff 598K Jan 31 18:47 gulliver.txt
-rw-r--r-- 1 humanist staff 583K Feb 1 22:53 33504-0.txt
drwxr-xr-x 2 humanist staff 68 Feb 2 00:58 backupIn this episode we’ll focus on the dataset
2014-01_JA.tsv, that contains journal article metadata, and
the three .tsv files derived from the original dataset.
Each of these three .tsv files includes all data where a
keyword such as africa or america appears in
the ‘Title’ field of 2014-01_JA.tsv.
CSV and TSV Files
CSV (Comma-separated values) is a common plain text format for
storing tabular data, where each record occupies one line and the values
are separated by commas. TSV (Tab-separated values) is the same except
that values are separated by tabs rather than commas. Confusingly, CSV
is sometimes used to refer to both CSV, TSV and variations of them. The
simplicity of the formats make them great for exchange and archival.
They are not bound to a specific program (unlike Excel files, say, there
is no CSV program, just lots and lots of programs that
support the format, including Excel by the way.), and you wouldn’t have
any problems opening a 40 year old file today if you came across
one.
First, let’s have a look at the largest data file, using the tools we learned in Reading files:
Like 829-0.txt before, the whole dataset cascades by and
can’t really make any sense of that amount of text. To cancel this
on-going concatenation, or indeed any process in the Unix
shell, press Ctrl+C.
In most data files a quick glimpse of the first few lines already tells us a lot about the structure of the dataset, for example the table/column headers:
OUTPUT
File Creator Issue Volume Journal ISSN ID Citation Title Place Labe Language Publisher Date
History_1a-rdf.tsv Doolittle, W. E. 1 59 KIVA -ARIZONA- 0023-1940 (Uk)RN001571862 KIVA -ARIZONA- 59(1), 7-26. (1993) A Method for Distinguishing between Prehistoric and Recent Water and Soil Control Features xxu eng ARIZONA ARCHAEOLOGICAL AND HISTORICAL SOCIETY 1993
History_1a-rdf.tsv Nelson, M. C. 1 59 KIVA -ARIZONA- 0023-1940 (Uk)RN001571874 KIVA -ARIZONA- 59(1), 27-48. (1993) Classic Mimbres Land Use in the Eastern Mimbres Region, Southwestern New Mexico xxu eng ARIZONA ARCHAEOLOGICAL AND HISTORICAL SOCIETY 1993
In the header, we can see the common metadata fields of academic
papers: Creator, Issue, Citation,
etc.
Next, let’s learn about a basic data analysis tool: wc
is the “word count” command: it counts the number of lines, words, and
bytes. Since we love the wildcard operator, let’s run the command
wc *.tsv to get counts for all the .tsv files
in the current directory (it takes a little time to complete):
OUTPUT
13712 511261 3773660 2014-01-31_JA-africa.tsv
27392 1049601 7731914 2014-01-31_JA-america.tsv
507732 17606310 131122144 2014-01_JA.tsv
5375 196999 1453418 2014-02-02_JA-britain.tsv
554211 19364171 144081136 totalThe first three columns contains the number of lines, words and bytes.
If we only have a handful of files to compare, it might be faster or more convenient to check with Microsoft Excel, OpenRefine or your favourite text editor, but when we have tens, hundreds or thousands of documents, the Unix shell has a clear speed advantage. The real power of the shell comes from being able to combine commands and automate tasks, though. We will touch upon this slightly.
For now, we’ll see how we can build a simple pipeline to find the
shortest file in terms of number of lines. We start by adding the
-l flag to get only the number of lines, not the number of
words and bytes:
OUTPUT
13712 2014-01-31_JA-africa.tsv
27392 2014-01-31_JA-america.tsv
507732 2014-01_JA.tsv
5375 2014-02-02_JA-britain.tsv
554211 totalThe wc command itself doesn’t have a flag to sort the
output, but as we’ll see, we can combine three different shell commands
to get what we want.
First, we have the wc -l *.tsv command. We will save the
output from this command in a new file. To do that, we redirect
the output from the command to a file using the ‘greater than’ sign
(>), like so:
There’s no output now since the output went into the file
lengths.txt, but we can check that the output indeed ended
up in the file using cat or less (or Notepad
or any text editor).
OUTPUT
13712 2014-01-31_JA-africa.tsv
27392 2014-01-31_JA-america.tsv
507732 2014-01_JA.tsv
5375 2014-02-02_JA-britain.tsv
554211 totalNext, there is the sort command. We’ll use the
-n flag to specify that we want numerical sorting, not
lexical sorting, we output the results into yet another file, and we use
cat to check the results:
OUTPUT
5375 2014-02-02_JA-britain.tsv
13712 2014-01-31_JA-africa.tsv
27392 2014-01-31_JA-america.tsv
507732 2014-01_JA.tsv
554211 totalFinally we have our old friend head, that we can use to
get the first line of the sorted-lengths.txt:
OUTPUT
5375 2014-02-02_JA-britain.tsvBut we’re really just interested in the end result, not the
intermediate results now stored in lengths.txt and
sorted-lengths.txt. What if we could send the results from
the first command (wc -l *.tsv) directly to the next
command (sort -n) and then the output from that command to
head -n 1? Luckily we can, using a concept called pipes. On
the command line, you make a pipe with the vertical bar character
|. Let’s try with one pipe first:
OUTPUT
5375 2014-02-02_JA-britain.tsv
13712 2014-01-31_JA-africa.tsv
27392 2014-01-31_JA-america.tsv
507732 2014-01_JA.tsv
554211 totalNotice that this is exactly the same output that ended up in our
sorted-lengths.txt earlier. Let’s add another pipe:
OUTPUT
5375 2014-02-02_JA-britain.tsvIt can take some time to fully grasp pipes and use them efficiently, but it’s a very powerful concept that you will find not only in the shell, but also in most programming languages.

Pipes and Filters
This simple idea is why Unix has been so successful. Instead of
creating enormous programs that try to do many different things, Unix
programmers focus on creating lots of simple tools that each do one job
well, and that work well with each other. This programming model is
called “pipes and filters”. We’ve already seen pipes; a filter is a
program like wc or sort that transforms a
stream of input into a stream of output. Almost all of the standard Unix
tools can work this way: unless told to do otherwise, they read from
standard input, do something with what they’ve read, and write to
standard output.
The key is that any program that reads lines of text from standard input and writes lines of text to standard output can be combined with every other program that behaves this way as well. You can and should write your programs this way so that you and other people can put those programs into pipes to multiply their power.
Adding another pipe
We have our wc -l *.tsv | sort -n | head -n 1 pipeline.
What would happen if you piped this into cat? Try it!
Count the number of words, sort and print (faded example)
To count the total lines in every tsv file, sort the
results and then print the first line of the file we use the
following:
Now let’s change the scenario. We want to know the 10 files that
contain the most words. Check the manual for the
wc command (either using man wc or
wc --help) to see if you can find out what flag to use to
print out the number of words (but not the number of lines and bytes).
Fill in the blanks below to count the words for each file, put them into
order, and then make an output of the 10 files with the most words
(Hint: The sort command sorts in ascending order by default).
Counting number of files
Let’s make a different pipeline. You want to find out how many files
and directories there are in the current directory. Try to see if you
can pipe the output from ls into wc to find
the answer.
Writing to files
The date command outputs the current date and time. Can
you write the current date and time to a new file called
logfile.txt? Then check the contents of the file.
Appending to a file
While > writes to a file, >>
appends something to a file. Try to append the current date and time to
the file logfile.txt?
Counting the number of words
We learned about the -w flag above, so now try using it with the
.tsv files.
If you have time, you can also try to sort the results by piping it
to sort. And/or explore the other flags of
wc.
From man wc, you will see that there is a
-w flag to print the number of words:
OUTPUT
-w The number of words in each input file is written to the standard
output.So to print the word counts of the .tsv files:
OUTPUT
511261 2014-01-31_JA-africa.tsv
1049601 2014-01-31_JA-america.tsv
17606310 2014-01_JA.tsv
196999 2014-02-02_JA-britain.tsv
19364171 totalAnd to sort the lines numerically:
OUTPUT
196999 2014-02-02_JA-britain.tsv
511261 2014-01-31_JA-africa.tsv
1049601 2014-01-31_JA-america.tsv
17606310 2014-01_JA.tsv
19364171 totalMining or searching
Searching for something in one or more files is something we’ll often
need to do, so let’s introduce a command for doing that:
grep (short for global regular expression
print). As the name suggests, it supports regular expressions
and is therefore only limited by your imagination, the shape of your
data, and - when working with thousands or millions of files - the
processing power at your disposal.
To begin using grep, first navigate to the
shell-lesson directory if not already there. Then create a
new directory “results”:
Now let’s try our first search:
Remember that the shell will expand *.tsv to a list of
all the .tsv files in the directory. grep will
then search these for instances of the string “1999” and print the
matching lines. There were a lot of instances of 1999 in
the tsv files. Let’s try getting their count instead of
instances.
Strings
A string is a sequence of characters, or “a piece of text”.
We’re going to run the same commad with the option -c
for count. Press the up arrow once in order to cycle back to your most
recent action. Amend grep 1999 *.tsv to
grep -c 1999 *.tsv and press enter.
OUTPUT
2014-01-31_JA-africa.tsv:804
2014-01-31_JA-america.tsv:1478
2014-01_JA.tsv:28767
2014-02-02_JA-britain.tsv:284The shell now prints the number of times the string 1999 appeared in each file. If you look at the output from the previous command, this tends to refer to the date field for each journal article.
We will try another search:
OUTPUT
2014-01-31_JA-africa.tsv:20
2014-01-31_JA-america.tsv:34
2014-01_JA.tsv:867
2014-02-02_JA-britain.tsv:9We got back the counts of the instances of the string
revolution within the files. Now, amend the above command
to the below and observe how the output of each is different:
OUTPUT
2014-01-31_JA-africa.tsv:118
2014-01-31_JA-america.tsv:1018
2014-01_JA.tsv:9327
2014-02-02_JA-britain.tsv:122This repeats the query, but prints a case insensitive count
(including instances of both revolution and
Revolution and other variants). Note how the count has
increased nearly 30 fold for those journal article titles that contain
the keyword ‘america’. As before, cycling back and adding
> results/, followed by a filename (ideally in .txt
format), will save the results to a data file.
So far we have counted strings in files and printed to the shell or
to file those counts. But the real power of grep comes in
that you can also use it to create subsets of tabulated data (or indeed
any data) from one or multiple files.
This script looks in the defined files and prints any lines
containing revolution (without regard to case) to the
shell. We let the shell add today’s date to the filename:
This saves the subsetted data to a new file.
Alternative date commands
This way of writing dates is so common that on most platforms you can
get the same result by typing $(date -I) instead of
$(date "+%Y-%m-%d").
However, if we look at this file, it contains every instance of the
string ‘revolution’ including as a single word and as part of other
words such as ‘revolutionary’. This perhaps isn’t as useful as we
thought… Thankfully, the -w flag instructs
grep to look for whole words only, giving us greater
precision in our search.
This script looks in both of the defined files and exports any lines
containing the whole word revolution (without regard to
case) to the specified .tsv file.
We can show the difference between the files we created.
OUTPUT
10585 2016-07-19_JAi-revolution.tsv
7779 2016-07-19_JAiw-revolution.tsv
18364 totalAutomatically adding a date prefix
Notice how we didn’t type today’s date ourselves, but let the
date command do that mindless task for us. Find out about
the "+%Y-%m-%d" option and alternative options we could
have used.
Using date --help (on Git Bash for Windows or Linux) or
man date (on macOS or Linux) will show you that the
+ option introduces a date format, where %Y,
%m and %d are replaced by the year, month, and
day respectively. There are many other percent-codes you could use.
You might also see that -I is short for --iso-8601, which
essentially avoids the confusion between the European and American date
formats DD.MM.YYYY and MM/DD/YYYY.
Finally, we’ll use the regular expression syntax covered earlier to search for similar words.
Basic, extended, and PERL-compatible regular expressions
There are, unfortunately, different
ways of writing regular expressions. Across its various versions,
grep supports “basic”, at least two types of “extended”,
and “PERL-compatible” regular expressions. This is a common cause of
confusion, since most tutorials, including ours, teach regular
expressions compatible with the PERL programming language, but
grep uses basic by default. Unless you want to remember the
details, make your life easy by always using the most advanced regular
expressions your version of grep supports (-E
flag on macOS X, -P on most other platforms) or when doing
something more complex than searching for a plain string.
The regular expression ‘fr[ae]nc[eh]’ will match “france”, “french”, but also “frence” and “franch”. It’s generally a good idea to enclose the expression in single quotation marks, since that ensures the shell sends it directly to grep without any processing (such as trying to expand the wildcard operator *).
The shell will print out each matching line.
We include the -o flag to print only the matching part
of the lines e.g. (handy for isolating/checking results):
Pair up with your neighbor and work on these exercises:
Case sensitive search
Search for all case sensitive instances of a whole word you choose in
all four derived .tsv files in this directory. Print your
results to the shell.
Case sensitive search in select files
Search for all case sensitive instances of a word you choose in the
‘America’ and ‘Africa’ .tsv files in this directory. Print
your results to the shell.
Count words (case sensitive)
Count all case sensitive instances of a word you choose in the
‘America’ and ‘Africa’ .tsv files in this directory. Print
your results to the shell.
Count words (case insensitive)
Count all case insensitive instances of that word in the ‘America’
and ‘Africa’ .tsv files in this directory. Print your
results to the shell.
Case insensitive search in select files
Search for all case insensitive instances of that word in the
‘America’ and ‘Africa’ .tsv files in this directory. Print
your results to a file results/hero.tsv.
Case insensitive search in select files (whole word)
Search for all case insensitive instances of that whole word in the
‘America’ and ‘Africa’ .tsv files in this directory. Print
your results to a file results/hero-i.tsv.
Searching with regular expressions
Use regular expressions to find all ISSN numbers (four digits
followed by hyphen followed by four digits) in
2014-01_JA.tsv and print the results to a file
results/issns.tsv. Note that you might have to use the
-E flag (or -P with some versions of
grep, e.g. with Git Bash on Windows).
or
It is worth checking the file to make sure grep has
interpreted the pattern correctly. You could use the less
command for this.
The -o flag means that only the ISSN itself is printed
out, instead of the whole line.
If you came up with something more advanced, perhaps including word boundaries, please share your result in the collaborative document and give yourself a pat on the shoulder.
Finding unique values
If you pipe something to the uniq command, it will
filter out adjacent duplicate lines. In order for the ‘uniq’ command to
only return unique values though, it needs to be used with the ‘sort’
command. Try piping the output from the command in the last exercise to
sort and then piping these results to ‘uniq’ and then
wc -l to count the number of unique ISSN values.
Using a Loop to Count Words
We will now use a loop to automate the counting of certain words
within a document. For this, we will be using the Little
Women e-book from Project
Gutenberg. The file is inside the shell-lesson folder
and named pg514.txt. Let’s rename the file to
littlewomen.txt.
$ mv pg514.txt littlewomen.txtThis renames the file to something easier to remember.
Now let’s create our loop. In the loop, we will ask the computer to go through the text, looking for each girl’s name, and count the number of times it appears. The results will print to the screen.
BASH
$ for name in "Jo" "Meg" "Beth" "Amy"
> do
> echo "$name"
> grep -wo "$name" littlewomen.txt | wc -l
> doneOUTPUT
Jo
1355
Meg
683
Beth
459
Amy
645What is happening in the loop?
-
echo "$name"is printing the current value of$name -
grep "$name" littlewomen.txtfinds each line that contains the value stored in$name. The-wflag finds only the whole word that is the value stored in$nameand the-oflag pulls this value out from the line it is in to give you the actual words to count as lines in themselves. - The output from the
grepcommand is redirected with the pipe,|(without the pipe and the rest of the line, the output fromgrepwould print directly to the screen) -
wc -lcounts the number of lines (because we used the-lflag) sent fromgrep. Becausegreponly returned lines that contained the value stored in$name,wc -lcorresponds to the number of occurrences of each girl’s name.
Why are the variables double-quoted here?
In episode 8 we learned to use
"$..."as a safeguard against white-space being misinterpreted. Why could we omit the"-quotes in the above example?What happens if you add
"Louisa May Alcott"to the first line of the loop and remove the"from$namein the loop’s code?
Because we are explicitly listing the names after
in, and those contain no white-space. However, for consistency it’s better to use rather once too often than once too rarely.Without
"-quoting$name, the last loop will try to executegrep Louisa May Alcott littlewomen.txt.grepinterprets only the first word as the search pattern, butMayandAlcottas filenames. This produces two errors and a possibly untrustworthy count:
Selecting columns from our article dataset
When you receive data it will often contain more columns or variables
than you need for your work. If you want to select only the columns you
need for your analysis, you can use the cut command to do
so. cut is a tool for extracting sections from a file. For
instance, say we want to retain only the Creator,
Volume, Journal, and Citation
columns from our article data. With cut we’d:
OUTPUT
Creator Volume Journal Citation
Doolittle, W. E. 59 KIVA -ARIZONA- KIVA -ARIZONA- 59(1), 7-26. (1993)
Nelson, M. C. 59 KIVA -ARIZONA- KIVA -ARIZONA- 59(1), 27-48. (1993)
Deegan, A. C. 59 KIVA -ARIZONA- KIVA -ARIZONA- 59(1), 49-64. (1993)
Stone, T. 59 KIVA -ARIZONA- KIVA -ARIZONA- 59(1), 65-82. (1993)
Adams, W. Y. 1 NORTHEAST AFRICAN STUDIES NORTHEAST AFRICAN STUDIES 1(2/3), 7-18. (1994)
Beswick, S. F. 1 NORTHEAST AFRICAN STUDIES NORTHEAST AFRICAN STUDIES 1(2/3), 19-48. (1994)
Cheeseboro, A. Q. 1 NORTHEAST AFRICAN STUDIES NORTHEAST AFRICAN STUDIES 1(2/3), 49-74. (1994)
Duany, W. 1 NORTHEAST AFRICAN STUDIES NORTHEAST AFRICAN STUDIES 1(2/3), 75-102. (1994)
Mohamed Ibrahim Khalil 1 NORTHEAST AFRICAN STUDIES NORTHEAST AFRICAN STUDIES 1(2/3), 103-118. (1994)Above we used cut and the -f flag to
indicate which columns we want to retain. cut works on tab
delimited files by default. We can use the flag -d to
change this to a comma, or semicolon or another delimiter. If you are
unsure of your column position and the file has headers on the first
line, we can use head -n 1 <filename> to print those
out.
First, let’s see where our desired columns are:
OUTPUT
File Creator Issue Volume Journal ISSN ID Citation Title Place Labe Language Publisher DateOk, now we know Issue is column 3, Volume
4, Language 11, and Publisher 12. We use these
positional column numbers to construct our cut command:
cut -f 3,4,11,12 2014-01_JA.tsv > 2014-01_JA_ivlp.tsvWe can confirm this worked by running head on the file:
head 2014-01_JA_ivlp.tsvOUTPUT
Issue Volume Language Publisher
1 59 eng ARIZONA ARCHAEOLOGICAL AND HISTORICAL SOCIETY
1 59 eng ARIZONA ARCHAEOLOGICAL AND HISTORICAL SOCIETY
1 59 eng ARIZONA ARCHAEOLOGICAL AND HISTORICAL SOCIETY
1 59 eng ARIZONA ARCHAEOLOGICAL AND HISTORICAL SOCIETY- The shell can be used to count elements of documents
- The shell can be used to search for patterns within files
- Commands can be used to count and mine any number of files
- Commands and flags can be combined to build complex queries specific to your work
Content from Working with free text
Last updated on 2026-06-23 | Edit this page
Overview
Questions
- How do we work with complex files?
Objectives
- Use shell tools to clean and transform free text
Working with free text
So far we have looked at how to use the Unix shell to manipulate, count, and mine tabulated data. Some library data, especially digitised documents, is much messier than tabular metadata. Nonetheless, many of the same techniques can be applied to non-tabulated data such as free text. We need to think carefully about what it is we are counting and how we can get the best out of the Unix shell.
Thankfully there are plenty of folks out there doing this sort of work and we can borrow what they do as an introduction to working with these more complex files. So for this final exercise we’re going to leap forward a little in terms of difficulty to a scenario where we won’t learn about everything that is happening in detail or discuss at length each command. We’re going to prepare and pull apart texts to demonstrate some of the potential applications of the Unix shell. And where commands we’ve learnt about are used, I’ve left some of the figuring out to do to you - so please refer to your notes if you get stuck!
Before going any further, speak to the person next to you and choose which type of text you’d like to work on together. You have three options:
- Option 1: An example of hand transcribed text: Gulliver’s Travels (1735)
- Option 2: An example of text captured by an optical character recognition process: General Report on the Physiography of Maryland. A dissertation, etc. (Reprinted from Report of Maryland State Weather Service.) [With maps and illustrations.] 1898 (Retrieved from doi.org/10.21250/db12)
- Option 3: An example of a webpage: Piper’s World (a GeoCities page from 1999 saved at archive.org)
Option 1: Hand transcribed text
Grabbing a text, cleaning it up
We’re going to work with the gulliver.txt file, which we
made in Episode 3,
‘Working with files and directories’. You should (still) be working
in the shell-lesson directory.
Let’s look at the file.
OUTPUT
1 <U+FEFF>The Project Gutenberg eBook, Gulliver's Travels, by Jonatha
1 n Swift
2
3
4 This eBook is for the use of anyone anywhere at no cost and with
5 almost no restrictions whatsoever. You may copy it, give it away o
5 r
6 re-use it under the terms of the Project Gutenberg License included
7 with this eBook or online at www.gutenberg.org
8
9
10
11
12
13 Title: Gulliver's Travels
14 into several remote nations of the world
15
16
17 Author: Jonathan Swift
18
19
20
21 Release Date: June 15, 2009 [eBook #829]
22
23 Language: English
24
25 Character set encoding: UTF-8
26
27
28 ***START OF THE PROJECT GUTENBERG EBOOK GULLIVER'S TRAVELS***
29
30
31 Transcribed from the 1892 George Bell and Sons edition by David Pri
31 ce,
32 email ccx074@pglaf.org
33
34
35We’re going to start by using the sed command. The
command allows you to edit files directly.
The command sed in combination with the d
value will look at gulliver.txt and delete all values
between the rows specified. The > action then prompts
the script to this edited text to the new file specified.
This does the same as before, but for the header.
You now have a cleaner text. The next step is to prepare it even further for rigorous analysis.
We now use the tr command, used for translating or
deleting characters. Type and run:
This uses the translate command and a special syntax to remove all
punctuation ([:punct:]) and carriage returns
(\r). It also requires the use of both the output redirect
> we have seen and the input redirect <
we haven’t seen.
Finally, regularise the text by removing all the uppercase lettering.
Open the gulliver-clean.txt in a text editor. Note how
the text has been transformed ready for analysis.
Pulling a text apart, counting word frequencies
We are now ready to pull the text apart.
Here we’ve made extended use of the pipes we saw in Counting and mining with the shell.
The first part of this script uses the translate command again, this
time to translate every blank space into \n which renders
as a new line. Every word in the file will at this stage have its own
line.
The second part uses the sort command to rearrange the
text from its original order into an alphabetical configuration.
The third part uses uniq, another new command, in
combination with the -c flag to remove duplicate lines and
to produce a word count of those duplicates.
The fourth and final part sorts the text again by the counts of duplicates generated in step three.
Challenge
There are still some remaining punctuation marks in the text. They
are called ‘smart’ or ‘curly’ quotes. Can you remove them using
sed?
Hint: These quote marks are not among the 128 characters of the ASCII
standard, so in the file they are encoded using a different standard,
UTF-8. While this is no problem for sed, the window you are
typing into may not understand UTF-8. If so you will need to use a Bash
script; we encountered these at the end of episode 4, ‘Automating the
tedious with loops’.
As a reminder, use the text editor of your choice to write a file that looks like this:
BASH
#!/bin/bash
# This script removes quote marks from gulliver-clean.txt and saves the result as gulliver-noquotes.txt
(replace this line with your solution)Save the file as remove-quotes.sh and run it from the
command line like this:
BASH
#!/bin/bash
# This script removes quote marks from gulliver-clean.txt and saves the result as gulliver-noquotes.txt
sed -Ee 's/[""‘']//g' gulliver-clean.txt > gulliver-noquotes.txtIf this doesn’t work for you, you might need to check whether your text editor can save files using the UTF-8 encoding.
We have now taken the text apart and produced a count for each word
in it. This is data we can prod and poke and visualise, that can form
the basis of our investigations, and can compare with other texts
processed in the same way. And if we need to run a different set of
transformation for a different analysis, we can return to
gulliver-clean.txt to start that work.
And all this using a few commands on an otherwise unassuming but very powerful command line.
Option 2: Optical character recognised text
Grabbing a text, cleaning it up
We’re going to work with 201403160_01_text.json.
Let’s look at the file.
OUTPUT
1 [[1, ""], [2, ""], [3, ""], [4, ""], [5, ""], [6, ""], [7, "A GENERAL RE
1 PORT ON THE PHYSIOGRAPHY OF MARYLAND A DISSERTATION PRESENTED TO THE PRE
1 SIDENT AND FACULTY OF THE JOHNS HOPKINS UNIVERSITY FOR THE DEGREE OF DOC
1 TOR OF PHILOSOPHY BY CLEVELAND ABBE, Jr. BALTIMORE, MD. MAY, 1898."], [8
1 , ""], [9, ""], [10, "A MAP S H OW I N G THE PHYSIOGRAPHIC PROVINCES OF
1 MARYLAND AND Their Subdivisions Scale 1 : 2,000.000. 32 Miles-1 Inch"],
1 [11, "A GENERAL REPORT ON THE PHYSIOGRAPHY OF MARYLAND A DISSERTATION PR
1 ESENTED TO THE PRESIDENT AND FACULTY OF THE JOHNS HOPKINS UNIVERSITY FOR
1 THE DEGREE OF DOCTOR OF PHILOSOPHY BY CLEVELAND ABBE, Jr. BALTIMORE, MD
1 . MAY, 1898."], [12, "PRINTED BY tL%t jfricbcnrtxifti Compang BALTIMORE,
1 MD., U. S. A. REPRINTED FROM Report of Maryland State Weather Service,
1 Vol. 1, 1899, pp. 41-216."], [13, "A GENERAL REPORT ON THE PHYSIOGRAPHY
1 OF MARYLAND Physiographic Processes. INTRODUCTION. From the earliest tim
1 es men have observed more or less closely the various phenomena which na
1 ture presents, and have sought to find an explanation for them. Among th
1 e most interesting of these phe nomena have been those which bear on the
1 development of the sur face features of the earth or its topography. Im
1 pressed by the size and grandeur of the mountains, their jagged crests a
1 nd scarred sides, early students of geographical features were prone to
1 ascribe their origin to great convulsions of the earth's crust, earthqua
1 kes and vol canic eruptions. One generation after another comes and goes
1 , yet the mountains continue to rear their heads to the same heights, th
1 e rivers to run down the mountain sides in the same courses and follow tWe’re going to start by using the tr command, used for
translating or deleting characters. Type and run:
This uses the translate command and a special syntax to remove all
punctuation. It also requires the use of both the output redirect
> we have seen and the input redirect <
we haven’t seen.
Finally regularise the text by removing all the uppercase lettering.
Open the 201403160_01_text-clean.txt in a text editor.
Note how the text has been transformed ready for analysis.
Pulling a text apart, counting word frequencies
We are now ready to pull the text apart.
BASH
$ tr ' ' '\n' < 201403160_01_text-clean.txt | sort | uniq -c | sort -nr > 201403160_01_text-final.txtHere we’ve made extended use of the pipes we saw in Counting and mining with the shell.
The first part of this script uses the translate command again, this
time to translate every blank space into \n which renders
as a new line. Every word in the file will at this stage have its own
line.
The second part uses the sort command to rearrange the
text from its original order into an alphabetical configuration.
The third part uses uniq, another new command, in
combination with the -c flag to remove duplicate lines and
to produce a word count of those duplicates.
The fourth and final part sorts the text again by the counts of duplicates generated in step three.
Note: your final output will have one problem - not all the words counted are real words (see the words counted only 1 or 2 times). To better understand what has happened, search online to find out more about Optical Character Recognition of texts
Either way we have now taken the text apart and produced a count for
each word in it. This is data we can prod and poke and visualise, that
can form the basis of our investigations, and can compare with other
texts processed in the same way. And if we need to run a different set
of transformation for a different analysis, we can return to
201403160_01_text-clean.txt to start that work.
And all this using a few commands on an otherwise unassuming but very powerful command line.
Option 3: A webpage
Grabbing a text, cleaning it up
We’re going to work with diary.html.
Let’s look at the file.
OUTPUT
1 <!-- This document was created with HomeSite v2.5 -->
2 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2//EN">
3 <html>
4
5 <head>
6
7
8 <script type="text/javascript" src="/static/js/analytics.js"></script>
9 <script type="text/javascript">archive_analytics.values.server_name="www
9 b-app6.us.archive.org";archive_analytics.values.server_ms=105;</script>
10 <link type="text/css" rel="stylesheet" href="/static/css/banner-styles.c
10 ss"/>
11
12
13 <title>Piper's Diary</title>
14 <meta name="description"
15 content="Come visit our shih tzu, Piper. He has his very own photo gall
15 ary, monthly diary, newsletter, and dog site award. He also maintains d
15 og book reviews and quotations. Come check him out!">
16 <meta name="keywords"
17 content="shih tzu, dog, pet, quotations, award, diary, advice, book, rev
17 iew, piper">
18 <style TYPE="text/css" TITLE="Basic Fonts">
We’re going to start by using the sed command. The
command allows you to edit files directly.
The command sed in combination with the d
value will look at diary.html and delete all values between
the rows specified. The > action then prompts the script
to this edited text to the new file specified.
This does the same as before, but for the header.
You now have a cleaner text. The next step is to prepare it even further for rigorous analysis.
First we wil remove all the html tags. Type and run:
Here we are using a regular expression (see the Library
Carpentry regular expression lesson to find all valid html tags
(anything within angle brackets) and delete them). This is a complex
regular expression, so don’t worry too much about how it works! The
script also requires the use of both the output redirect
> we have seen and the input redirect <
we haven’t seen.
We’re going to start by using the tr command, used for
translating or deleting characters. Type and run:
This uses the translate command and a special syntax to remove all
punctuation ([:punct:]) and carriage returns
(\r).
Finally regularise the text by removing all the uppercase lettering.
Open the diary-clean.txt in a text editor. Note how the
text has been transformed ready for analysis.
Pulling a text apart, counting word frequencies
We are now ready to pull the text apart.
Here we’ve made extended use of the pipes we saw in Counting and mining with the shell.
The first part of this script uses the translate command again, this
time to translate every blank space into \n which renders
as a new line. Every word in the file will at this stage have its own
line.
The second part uses the sort command to rearrange the
text from its original order into an alphabetical configuration.
The third part uses uniq, another new command, in
combination with the -c flag to remove duplicate lines and
to produce a word count of those duplicates.
The fourth and final part sorts the text again by the counts of duplicates generated in step three.
We have now taken the text apart and produced a count for each word
in it. This is data we can prod and poke and visualise, that can form
the basis of our investigations, and can compare with other texts
processed in the same way. And if we need to run a different set of
transformation for a different analysis, we can return to
diary-final.txt to start that work.
And all this using a few commands on an otherwise unassuming but very powerful command line.
Where to go next
- Deborah S. Ray and Eric J. Ray, Unix and Linux: visual quickstart guide, 4th edition (2009). Invaluable (and not expensive) as a reference guide - especially if you only use the command line sporadically!
- The Command Line Crash Course. ‘Learn UNIX the Hard Way’ – good for reminders of the basics.
- Automate the Boring Stuff.
- Another Coursera course, Programming for Everybody (Python) is available and lasts 10 weeks, if you have 2-4 hours to spare per week. Python is popular in research programming as it is readable, relatively simple, and very powerful.
- Bill Turkel and the Digital History community more broadly. The second lesson you did today was based on a lesson Bill has on his website and Bill is also a general editor of the Programming Historian. The Programming Historian is an open, collaborative book aimed at providing programming lessons to historians. Although the lessons are hooked around problems historians have, their lessons - which cover various programming languages - have a wide applicability - indeed today’s course is based on two lessons I wrote with Ian Milligan, an historian at Waterloo, Canada - for ProgHist. Bill also has a wonderful tutorial on ‘Named Entity Recognition with Command Line Tools in Linux’ which I thoroughly recommend if you want to automatically find, markup, and count names, places, and organisations in text files…
Conclusion
In this session you have learned to navigate the Unix shell, to undertake some basic file counting, concatenation and deletion, to query across data for common strings, to save results and derived data, and to prepare textual data for rigorous computational analysis.
This only scratches the surface of what the Unix environment is capable of. It is hoped, however, that this session has provided a taster sufficient to prompt further investigation and productive play.
Keep in mind that the full potential the tools can offer may only emerge upon embedding these skills into real projects. Nonetheless, being able to manipulate, count and mine thousands of files is extremely useful. Even a large collection of files which do not contain any alpha-numeric data elements, such as image files, can be easily sorted, selected and queried depending on the amount of description, of metadata contained in each filename. If not a prerequisite of working with the Unix, then taking the time to structure your data in a consistent and predictable manner is certainly a significant step towards getting the most out of Unix commands. And if you can find a way of using the Unix shell regularly - perhaps only to copy or amend files - you’ll keep the basics fresh, meaning that next time you have cause to use the Unix shell for more complex commands, you shouldn’t need to learn it all over again.
Reflection
- Use your terminal to make file on your desktop (or another location
you prefer) titled
open-humanities-pt2.txt. - Add some notes about things you want to remember (even pointers to where other files are, ideas you had today etc).
- add reflections to the bottom of your file.
Some questions to consider: 1. What is one way you might use the shell in your work? 1. What new questions do you have? 1. What about today changes how you might work.
Feedback
Use your sticky notes to give the instructors feedback for today.
- On the “good” color, share one thing you liked about today or something you are glad you learned.
- On the “need help” color, share one thing you are still confused about or one thing that could have been better
References
- Shell tools can be combined to powerful effect
- James Baker and Ian Milligan, ‘Counting and mining research data with Unix’, The Programming Historian (2014).
- Ian Milligan and James Baker, ‘Introduction to the Bash Command Line’, The Programming Historian (2014).
- William J. Turkel, ‘Named Entity Recognition with Command Line Tools in Linux’ (30 June 2013). The section ‘NER Demo’ is adapted from this and shared under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported.
- William J. Turkel, ‘Basic Text Analysis with Command Line Tools in Linux’ (15 June 2013). The sections ‘Grabbing a text, cleaning it up’ and ‘Pulling a text apart, counting word frequencies’ are adapted from this and shared under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported.
Content from What is Git/GitHub?
Last updated on 2026-06-23 | Edit this page
Overview
Questions
- What is Git?
- What is GitHub?
Objectives
- recognize why version control is useful
- distinguish between Git and GitHub
What is Version Control?
Version control is a name used for software which can help you record changes you make to the files in a directory on your computer. Version control software and tools (such as Git and Subversion/SVN) are often associated with software development, and increasingly, they are being used to collaborate in research and academic environments. Version control systems work best with plain text files such as documents or computer code, but modern version control systems can be used to track changes in most types of file.
At its most basic level, version control software helps us register and track sets of changes made to files on our computer. We can then reason about and share those changes with others. As we build up sets of changes over time, we begin to see some benefits.
Benefits of using version control?
- Collaboration - Version control allows us to define formalized ways we can work together and share writing and code. For example merging together sets of changes from different parties enables co-creation of documents and software across distributed teams.
- Versioning - Having a robust and rigorous log of changes to a file, without renaming files (v1, v2, final_copy)
- Rolling Back - Version control allows us to quickly undo a set of changes. This can be useful when new writing or new additions to code introduce problems.
- Understanding - Version control can help you understand how the code or writing came to be, who wrote or contributed particular parts, and who you might ask to help understand it better.
- Backup - While not meant to be a backup solution, using version control systems mean that your code and writing can be stored on multiple other computers.
There are many more reasons to use version control, and we’ll explore some of these in the library context, but first let’s learn a bit about a popular version control tool called Git.
What are Git and GitHub?
We often hear the terms Git and GitHub used interchangeably but they are slightly different things.
Git is one of the most widely used version control systems in the world. It is a free, open source tool that can be downloaded to your local machine and used for logging all changes made to a group of designated computer files (referred to as a “git repository” or “repo” for short) over time. It can be used to control file versions locally by you alone on your computer, but is perhaps most powerful when employed to coordinate simultaneous work on a group of files shared among distributed groups of people.
Rather than emailing documents with tracked changes and some comments and renaming different versions of files (example.txt, exampleV2.txt, exampleV3.txt) to differentiate them, we can use Git to save (or in Git parlance, “commit”) all that information with the document itself. This makes it easy to get an overview of all changes made to a file over time by looking at a log of all the changes that have been made. And all earlier versions of each file still remain in their original form: they are not overwritten, should we ever wish to “roll back” to them.
Git was originally developed to help software developers work collaboratively on software projects, but it can be and is used for managing revisions to any file type on a computer system, including text documents and spreadsheets. Once installed, interaction with Git is done through the Command Prompt in Windows, or the Terminal on Mac/Linux. Since Word documents contain special formatting, Git unfortunately cannot version control those, nor can it version control PDFs, though both file types can be stored in Git repositories.
How can understanding Git help with humanities research and projects?
- Enables you to contribute to, collaborate on, and support digital research projects
- Enables you to control changes to your files over time without keeping multiple copies of those files
GitHub on the other hand is a popular website for hosting and sharing Git repositories remotely. It offers a web interface and provides functionality and a mixture of both free and paid services for working with such repositories. The majority of the content that GitHub hosts is open source software, though increasingly it is being used for other projects such as open access journals (e.g. Journal of Open Source Software), blogs, and regularly updated text books. In addition to GitHub, there are other Git hosting services that offer many similar features such as GitLab, Bitbucket and Gitee.
How can GitHub help with humanities research and projects?
- A place to discover and reuse (“fork”) a huge amount of openly licensed digital projects and open source software
- A new and alternative means for publishing content online. Any GitHub repository can have its own project website, blog and wiki using GitHub Pages.
Uses in a Humanities Context
Consider these humanities scholarship scenarios:
Scenario 1: Documenting history and archival information
An interdisciplinary team of researchers are working with a community-based organization to collect, map, and preserve local historical information. They are hoping to supplement existing archival documents, including hundreds of photographs, videos, and interviews, with additional content from the community. The team would also like input so that the community can help identify the people and places they depict. She combs the web for examples of existing crowdsourcing projects, and even though they all appear unique to each institution, she notices quite a few seem to have almost the exact same functionality and structure. Rather than build a whole new version from scratch herself, she wishes there was a way to just copy the code of an existing one, and modify it to reflect her project. She notices the GitHub icon at the bottom of one of the projects she likes, but clicking on the link just brings her to a confusing directory of files and oddly labeled buttons such as “Fork”.
GitHub hosts many open-licensed projects and allows any user to fork any public project. By clicking the “fork” button, any GitHub user can almost instantaneously create their own version of an existing project. That “forked” project can be used as the basis for a new project, or can be used to work out new features that can be merged back into the original. (From: GitHub for Academics )
Scenario 2: Metadata in an archival collection
A religious scholar is adding metadata labels to artifacts that document indigenous ways of life: photos, documents, video, objects, and audio. She’s working with a group of graduate students and community, so they need to make sure edits don’t conflict. They also need to be able to undo any edits and preserve the original metadata. Once edits are complete, the whole group wants to review the changes before re-ingesting the spreadsheet of metadata into the repository.
The team can choose to use Git by itself to track changes and resolve conflicts or they can choose to use GitHub to host the project so that users can collaborate and review changes on the Web. Git will preserve the original metadata as well as all edits. GitHub will facilitate discussion about what changes should be made, who should make them, and why.
- Version control helps track changes to files and projects
- Git and GitHub are not the same
Content from Getting started with Git
Last updated on 2026-06-23 | Edit this page
Overview
Questions
- What are repositories and how are they created?
- What do
addandcommitmean? - How do I check the status of my repository?
Objectives
- create a Git repository
- track changes to files using the Git repository
- query the current status of the Git repository
Setting up Git
When we use Git on a new computer for the first time, we need to configure a few things. The basic elements of a configuration for Git are:
- your name and email address,
- what your preferred text editor is,
- the name of your default branch (branches are an important component of Git that we will cover later).
To start we will check in on our current Git configuration. Open your shell terminal window and type:
On MacOS, without any configuration your output might look like this:
OUTPUT
credential.helper=osxkeychainOn Windows, without any configuration your output might look like this:
OUTPUT
diff.astextplain.textconv=astextplain
filter.lfs.clean=git-lfs clean -- %f
filter.lfs.smudge=git-lfs smudge -- %f
filter.lfs.process=git-lfs filter-process
filter.lfs.required=true
http.sslbackend=openssl
http.sslcainfo=C:/Program Files/Git/mingw64/ssl/certs/ca-bundle.crt
core.autocrlf=true
core.fscache=true
core.symlinks=false
pull.rebase=false
credential.helper=manager-core
credential.https://dev.azure.com.usehttppath=true
init.defaultbranch=mainIf you have different output, then you may have your Git configured already. If you have not configured Git, we will do that together now. First, we will tell Git our user name and email.
Please note: You need to use the same email address in your Git configuration in the shell as you entered into GitHub when you created your GitHub account. Later in the lesson we will be using GitHub and the email addresses need to match. If you are concerned about privacy, please review GitHub’s instructions for keeping your email address private.
Type these two commands into your shell, replacing
Your Name and the email address with your own:
BASH
$ git config --global user.name "Your Name"
$ git config --global user.email "yourname@domain.name"If you enter the commands correctly, the shell will merely return a command prompt and no messages. To check your work, ask Git what your configuration is using the same command as above:
OUTPUT
user.name=Your Name
user.email=yourname@domain.nameLet’s also set our default text editor. A text editor is necessary with some of your Git work, and the default from Git is Vim, which is a text editor that is hard to learn at first. Therefore, we recommend setting a simpler text editor in your Git configuration for this lesson.
Text editors
There are a lot of text editors to choose from, and a lot of people are enthusiastic about their preferences. Vi and Vim are popular editors for users of the BASH shell. If you will be using Git or the Shell with a group of people for a project or for work, asking for recommendations or preferences can help you pick an editor to get started with. If you already have your favorite, then you can set it as your default editor with Git.
Any text editor can be made default by adding the correct file path
and command line options (see GitHub
help). However, the simplest core.editor value is
"nano -w" on Mac, Windows, and Linux.
For example:
Lastly, we need to set the name of our default branch to
main.
The init.defaultBranch value configures git to set the
default branch to main instead of master.
Creating a repository
A Git repository is a data structure used to track
changes to a set of project files over time. Repositories are stored
within the same directory as these project files, in a hidden directory
called .git. We can create a new git repository either by
using GitHub’s web interface, or
via the command line. Let’s use the command line to create a git
repository for the experiments that we’re going to do today.
First, we will create a new directory for our project and enter that directory. We will explain commands as we go along.
Using Git
One of the main barriers to getting started with Git is understanding the terminology necessary to executing commands. Although some of the language used in Git aligns with common-use words in English, other terms are not so clear. The best way to learn Git terminology - which consists of a number of verbs such as add, commit and push (preceded by the word ‘git’) - is to use it, which is what we will be doing during this lesson. We will explain these commands as we proceed from setting up a new version-controlled project to publishing our own website.
On a command line interface, Git commands are written as
git verb options, where verb is what we
actually want to do and options is additional optional
information which may be needed for the verb. So let’s get
started with our setup.
We will now create an empty git repository to track changes to our project. To do this we will use the git init command, which is short for initialise.
OUTPUT
Initialized empty Git repository in <your file path>/hello-world/.git/The hello-world directory is now a git repository.
If we run the ls command now (ls lists the
content of the hello-world directory), the repository might
seem empty; however, adding the -a flag for all files via
ls -a will show all hidden files, which in this case
includes the new hidden directory .git. Flags can be
thought of as command line options that can be added to shell
commands.
Note that whenever we use git via the command line, we need to
preface each command (or verb) with git, so that the
computer knows we are trying to get git to do something, rather than
some other program.
Displaying the current project’s status
We can run the git status command to display the current
state of a project. Let’s do that now.
OUTPUT
On branch main
No commits yet
nothing to commit (create/copy files and use "git add" to track)The output tells us that we are on the main branch (more on this later) and that we have nothing to commit (no unsaved changes).
Two steps: Adding and committing
We will now create and save our first project file. This is a two-step process. First, we add any files for which we want to save the changes to a staging area, then we commit those changes to the repository. This two-stage process gives us fine-grained control over what should and should not be included in a particular commit.
Let’s create a new file using the touch command, which
is a quick way to create an empty file.
The .md extension above signifies that we have chosen to
use the Markdown format, a lightweight markup language with plain text
formatting syntax. We will explore Markdown a bit later.
Let’s check the status of our project again.
OUTPUT
On branch main
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
index.md
nothing added to commit but untracked files present (use "git add" to track)This status is telling us that git has noticed a new file in our
directory that we are not yet tracking. With colourised output, the
filename will appear in red. To change this, and to tell Git we want to
track any changes we make to index.md, we use git add.
This adds our Markdown file to the staging area (the
area where git checks for file changes). To confirm this we want to use
git status again.
OUTPUT
On branch main
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: index.mdIf we are using colourised output, we will see that the filename has changed colour (from red to green). Git also tells us that there is a new file to be committed but, before we do that, let’s add some text to the file.
We will open the file index.md with any text editor we
have at hand (e.g. Notepad on Windows or TextEdit on Mac OSX) and enter
# Hello, world!. The hash character is one way of writing a
header with Markdown. Now, let’s save the file within the text editor
and check if Git has spotted the changes.
OUTPUT
On branch main
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: index.md
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: index.mdThis lets us know that git has indeed spotted the changes to our file, but that it hasn’t yet staged them, so let’s add the new version of the file to the staging area.
Now we are ready to commit our first changes. Commit is similar to ‘saving’ a file to Git. However, compared to saving, a commit provides a lot more information about the changes we have made, and this information will remain visible to us later.
OUTPUT
[main (root-commit) e9e8fd3] Add index.md
1 file changed, 1 insertion(+)
create mode 100644 index.mdWe can see that one file has changed and that we made one insertion,
which was a line with the text ‘#Hello, world!’. We can also see the
commit message ‘Add index.md’, which we added by using the
-m flag after git commit. The commit message
is used to record a short, descriptive, and specific summary of what we
did to help us remember later on without having to look at the actual
changes. If we just run git commit without the
-m option, Git will launch nano (or whatever other editor
we configured as core.editor) so that we can write a longer
message.
Having made a commit, we now have a permanent record of what was changed, and git has also recorded some additional metadata: who made the commit (you!) and when the commit was made (timestamp). You are building a mini-history of your process of working with the files in this directory.
More on the Staging Area
If you think of Git as taking snapshots of changes over the life of a
project, git add specifies what will go in a
snapshot (putting things in the staging area), and
git commit then actually takes the snapshot, and
makes a permanent record of it (as a commit). If you don’t have anything
staged when you type git commit, Git will prompt you to use
git commit -a or git commit --all, which is
kind of like gathering everyone for the picture! However, it’s
almost always better to explicitly add things to the staging area,
because you might commit changes you forgot you made. (Going back to
snapshots, you might get the extra with incomplete makeup walking on the
stage for the snapshot because you used -a!) Try to stage
things manually, or you might find yourself searching for “git undo
commit” more than you would like!

At the moment, our changes are only recorded locally, on our computer. If we wanted to work collaboratively with someone else they would have no way of seeing what we’ve done. We will fix that in the next episode by using GitHub to share our work.
- When you initialize a Git repository in a directory, Git starts tracking the changes you make inside that directory.
- This tracking creates a history of the way the files have changed over time.
- Git uses a two-step process to record changes to your files. Changes to files must first be added to the staging area, then committed to the Git repository.
Content from Sharing your work
Last updated on 2026-06-23 | Edit this page
Overview
Questions
- How can I use Git and GitHub to share my work?
- How do I link a local Git repository to GitHub?
- How do I move changes between a local Git repository and a GitHub repository?
- How can I see the differences between my current file and my most recent commit?
Objectives
- create a remote repository on GitHub
- link a local Git repository to a remote GitHub repository
- move changes between the local and remote repositories using
pushandpull - examine the difference between an edited file and the file’s most recently committed version
The power of sharing
The real power of Git lies in being able to share your work with others and in being able to work collaboratively. The best way to do this is to use a remote hosting platform. For this lesson, we are using GitHub. Let’s log in there now.
Create a repository on GitHub
Once we have logged in to GitHub, we can create a new repository by clicking the + icon in the upper-right corner of any page then selecting New repository. Let’s do this now.

- Click “New Repository”
Clicking New Repository will take you to a creation page
with different options. For this workshop, we are not using any of the
options available.
- Name your repository “hello-world.”
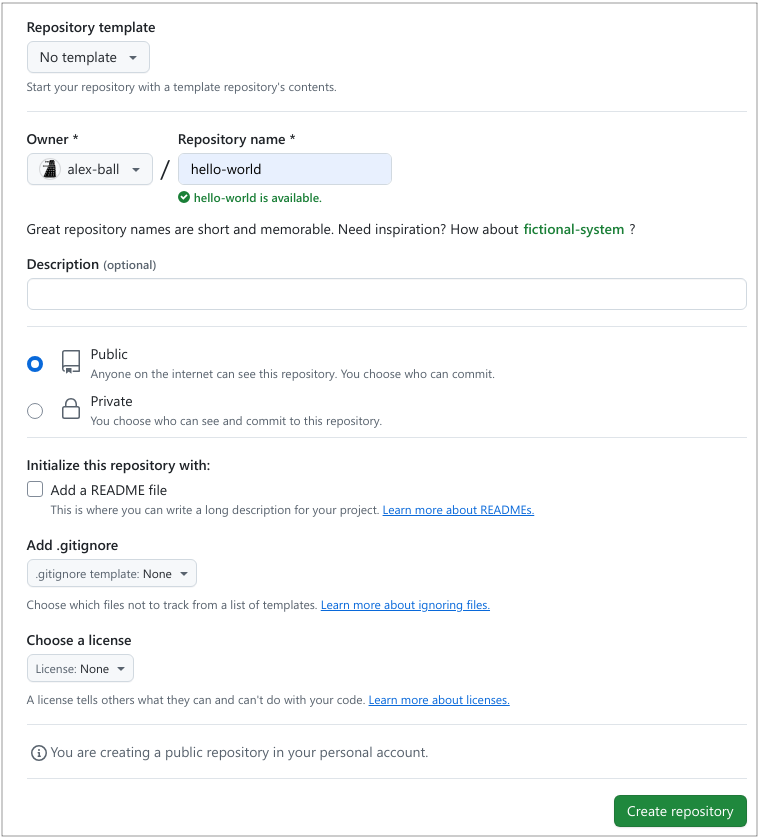
GitHub will ask if you want to add a README.md, license or a
.gitignore file. Do not do any of that for now – We want
you to start with a completely empty repository on GitHub.
- Click
Create Repositorybutton.
Choosing a license
When you are ready to use GitHub to host your own work, you should review the different license options. Choosing a license is an important part of openly sharing your creative and research work online. For help in wading through the many types of open source licenses, please visit https://choosealicense.com/.
Connecting your local repository to the GitHub repository
The next page that GitHub displays contains some information to help
you connect your repository on GitHub with your local repository (on
your own computer). To make this connection, we want to tell our local
repository that GitHub is the remote repository. In order
to do that we need the information that GitHub displays in the “Quick
setup” box on this page.
We will use the Secure Shell (SSH) protocol for this lesson, so please make sure that button shows that it is selected (gray highlight) and that the address in the text box starts with git@github. It will look something like this:
HTTPS vs. SSH
We use SSH here because, while it requires some additional configuration, it is a security protocol widely used by many applications. The steps below describe SSH at a minimum level for GitHub.
In the previous episode we created a local repository on our own computer. Now we have also created a remote repository on GitHub. But at this point, the two are completely isolated from each other. We want to link them together to synchronize them and share our project with the world.
To connect the repository on our own computer (local) to the repository we just created on GitHub, we will use the commands provided by GitHub in the box with the heading “…or push an existing repository from the command line.”
Let’s use these instructions now. Move back to your shell application and enter the first command:
Make sure to use the URL for your actual repository user name rather
than yourname: the only difference should be your username
instead of yourname.
Let’s breakdown the elements of the command. All commands related to
Git in the shell start by invoking the Git language by typing
git at the start. remote add is the command in
the Git language we use to configure a remote repository, e.g., another
Git repository that contains the same content as our local repository,
but that is not on our computer. origin is the nickname
we’re telling our local machine to use to for the following long web
address. After we enter this command, we can use origin to
refer to this specific repository in GitHub instead of the URL.
We can check that it is set up correctly with the command:
OUTPUT
origin git@github.com:<your_github_username>/hello-world.git (fetch)
origin git@github.com:<your_github_username>/hello-world.git (push)SSH Background and Setup
We still need to do a little more setup before we can actually connect to this remote repository. We need to set up a way for our local computer to authenticate with GitHub so that GitHub recognizes our computer as belonging to the same person who owns the GitHub repository.
We will use SSH as our authentication method. SSH stands for Secure SHell protocol. SSH is a cryptographic network protocol that allows secure communication between computers using an otherwise insecure network.
SSH uses what is called a key pair – two keys that work together to validate access. One key is used publicly (the public key) and the other key is kept private (the private key).
You can think of the public key as a padlock, and only you have the key (the private key) to open it. You use the public key where you want a secure method of communication, such as your GitHub account. You give this padlock, or public key, to GitHub and say “lock the communications to my account with this so that only computers that have my private key can unlock communications and send Git commands as my GitHub account.”
What we will do now is the minimum required to set up the SSH keys and add the public key to a GitHub account. I’m not going to lie, this is a bit tedious and confusing. But you have to do it to get to the fun part, so hang in there.
The first thing we are going to do is check if this has already been done on the computer you’re on.
Keeping your keys secure
You shouldn’t really forget about your SSH keys, since they keep your account secure. It’s good practice to audit your secure shell keys every so often. Especially if you are using multiple computers to access your account.
We will run the list command (ls) to check what key
pairs already exist on your computer. In our command we use the
~ as the shorthand for “my home directory.”
Your output is going to look a little different depending on whether or not SSH has ever been set up on the computer you are using.
If you have not set up SSH, your output might look like this:
OUTPUT
ls: cannot access '/c/Users/YourName/.ssh': No such file or directoryIf SSH has been set up on the computer you’re using, the public and
private key pairs will be listed. The file names are either
id_ed25519/id_ed25519.pub or
id_rsa/id_rsa.pub depending on how the key
pairs were set up.
If you do not have SSH set up, let’s set it up now. Use this command to create key pairs:
OUTPUT
Generating public/private ed25519 key pair.
Enter file in which to save the key (/c/Users/YourName/.ssh/id_ed25519):We want to use the default file, so just press Enter.
OUTPUT
Created directory '/c/Users/YourName/.ssh'.
Enter passphrase (empty for no passphrase):Your computer is now asking you for a passphrase to protect this SSH key pair. We recommend that you use a passphrase and that you make a note of it. There is no “reset my password” option for this setup. If you forget your passphrase, you have to delete your existing key pair and do this setup again. It’s not a big deal, but easier if you don’t have to repeat it.
OUTPUT
Enter same passphrase again:After entering the same passphrase a second time, you will receive the confirmation
OUTPUT
Your identification has been saved in /c/Users/YourName/.ssh/id_ed25519
Your public key has been saved in /c/Users/YourName/.ssh/id_ed25519.pub
The key fingerprint is:
SHA256:SMSPIStNyA00KPxuYu94KpZgRAYjgt9g4BA4kFy3g1o yourname@domain.name
The key's randomart image is:
+--[ED25519 256]--+
|^B== o. |
|%*=.*.+ |
|+=.E =.+ |
| .=.+.o.. |
|.... . S |
|.+ o |
|+ = |
|.o.o |
|oo+. |
+----[SHA256]-----+The “identification” is actually the private key. You should never share it. The public key is appropriately named. The “key fingerprint” is a shorter version of a public key.
Now that we have generated the SSH keys, we will find the SSH files when we check.
OUTPUT
drwxr-xr-x 1 YourName 197121 0 Jul 16 14:48 ./
drwxr-xr-x 1 YourName 197121 0 Jul 16 14:48 ../
-rw-r--r-- 1 YourName 197121 419 Jul 16 14:48 id_ed25519
-rw-r--r-- 1 YourName 197121 106 Jul 16 14:48 id_ed25519.pubNow we need to give our public key (the padlock) over to GitHub.
First, we need to copy the public key. Be sure to include the
.pub at the end, otherwise you’re looking at the private
key.
OUTPUT
ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIDmRA3d51X0uu9wXek559gfn6UFNF69yZjChyBIU2qKI yourname@domain.nameCopy that entire line of output, and we will paste the copied text into GitHub in the next step.
Now, going to GitHub.com, click on your profile icon in the top right corner to get the drop-down menu. Click “Settings,” then on the settings page, click “SSH and GPG keys,” on the left side “Account settings” menu. Click the “New SSH key” button on the right side. Now, you can add the title (A person might use the title “My 2021 work laptop,” just a little description to remind themselves which computer this public key connect to). Paste your SSH key into the field, and click the “Add SSH key” to complete the setup.
Now that we’ve set that up, let’s check our authentication from the command line.
OUTPUT
Hi YourName! You've successfully authenticated, but GitHub does not provide shell access.Pushing changes
Now we have established a connection between the two repositories,
but we still haven’t synchronized their content, so the remote
repository is still empty. To fix that, we will have to “push” our local
changes to the GitHub repository. We do this using the
git push command:
OUTPUT
Counting objects: 3, done.
Writing objects: 100% (3/3), 226 bytes | 0 bytes/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To https://github.com/<your_github_username/hello-world
* [new branch] main -> main
Branch main set up to track remote branch main from origin.The nickname of our remote repository is “origin” and the default
local branch name is “main”. The -u flag tells git to
remember the parameters, so that next time we can simply run
git push and Git will know what to do.
Pushing our local changes to the Github repository is sometimes
referred to as “pushing changes upstream to Github”. The
word upstream here comes from the git flag we used earlier
in the command git push -u origin main. The flag
-u refers to -set-upstream, so when we say
pushing changes upstream, it refers to the remote repository.
You may be prompted to enter your GitHub username and password to complete the command.
When we do a git push, we will see Git ‘pushing’ changes
upstream to GitHub. Because our file is very small, this won’t take long
but if we had made a lot of changes or were adding a very large
repository, we might have to wait a little longer. We can check where
we’re at with git status.
OUTPUT
On branch main
Your branch is up-to-date with 'origin/main'.
nothing to commit, working tree cleanThis output lets us know where we are working (the main branch). We can also see that we have no changes to commit and everything is in order.
We can use the git diff command to see changes we have
made before making a commit. Open index.md with any text editor and
enter some text on a new line, for instance “A new line” or something
else. We will then use git diff to see the changes we
made:
OUTPUT
diff --git a/index.md b/index.md
index aed0629..989787e 100644
--- a/index.md
+++ b/index.md
@@ -1 +1,2 @@
-# Hello, world!
\ No newline at end of file
+# Hello, world!
+A new lineThe command produces lots of information and it can be a bit overwhelming at first, but let’s go through some key information here:
- The first line tells us that Git is producing output similar to the
Unix
diffcommand, comparing the old and new versions of the file. - The second line tells exactly which versions of the file Git is
comparing;
aed0629and989787eare unique computer-generated identifiers for those versions. - The third and fourth lines once again show the name of the file being changed.
- The remaining lines are the most interesting; they show us the actual differences and the lines on which they occur. In particular, the + markers in the first column show where we have added lines.
We can now commit these changes:
If we are very forgetful and have already forgotten what we changed,
git log allows us to look at what we have been doing with
our git repository (in reverse chronological order, with the very latest
changes first).
OUTPUT
commit 8e2eb9920eaa0bf18a4adfa12474ad58b765fd06
Author: Your Name <your_email>
Date: Mon Jun 5 12:41:45 2017 +0100
Add another line
commit e9e8fd3f12b64fc3cbe8533e321ef2cdb1f4ed39
Author: Your Name <your_email>
Date: Fri Jun 2 18:15:43 2017 +0100
Add index.mdThis shows us the two commits we have made and shows the messages we wrote. It is important to try to use meaningful commit messages when we make changes. This is especially important when we are working with other people who might not be able to guess as easily what our short cryptic messages might mean. Note that it is best practice to always write commit messages in the imperative (e.g. ‘Add index.md’, rather than ‘Adding index.md’).
Pushing changes (again)
Now, let’s have a look at the repository at GitHub again (that is,
https://github.com/some-librarian/hello-world with
some-librarian replaced with your username). We see that
the index.md file is there, but there is only one
commit:

And if you click on index.md you will see that it
contains the “Hello, world!” header, but not the new line we just
added.
This is because we haven’t yet pushed our local changes to the remote repository. This might seem like a mistake in design but it is often useful to make a lot of commits for small changes so you are able to make careful revisions later and you don’t necessarily want to push all these changes one by one.
Another benefit of this design is that you can make commits without being connected to internet.
But let’s push our changes now, using the git push
command:
OUTPUT
Counting objects: 3, done.
Writing objects: 100% (3/3), 272 bytes | 0 bytes/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To https://github.com/<your_github_username>/hello-world
e9e8fd3..8e2eb99 main -> mainAnd let’s check on GitHub that we now have 2 commits there.
Pulling changes
When working with others, or when we’re making our own changes from different machines, we need a way of pulling those remote changes back into our local copy. For now, we can see how this works by making a change on the GitHub website and then ‘pulling’ that change back to our computer.
Let’s go to our repository in GitHub and make a change. Underneath where our index.md file is listed you will see a button to ‘Add a README’. Do this now, entering whatever you like, scrolling to the bottom and clicking ‘Commit new file’ (The default commit message will be ‘Create README.md’, which is fine for our purposes).
The README file
It is good practice to add a README file to each project to give a brief overview of what the project is about. If you put your README file in your repository’s root directory, GitHub will recognize and automatically surface your README to repository visitors
Our local repository is now out of sync with our remote repository,
so let’s fix that by pulling the remote changes into our local
repository using the git pull command.
OUTPUT
remote: Counting objects: 3, done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
Unpacking objects: 100% (3/3), done.
From https://github.com/<your_github_username>/hello-world
8e2eb99..0f5a7b0 main -> origin/main
Updating 8e2eb99..0f5a7b0
Fast-forward
README.md | 1 +
1 file changed, 1 insertion(+)
create mode 100644 README.mdThe above output shows that we have fast-forwarded our local
repository to include the file README.md. We could confirm this by
entering the ls command.
When we begin collaborating on more complex projects, we may have to consider more aspects of git functionality, but this should be a good start. In the next section, we can look more closely at collaborating and using GitHub pages to create a website for our project.
- remote repositories on GitHub help you collaborate and share your work
-
pushis a Git verb for sending changes from the local repository to a remote repository -
pullis a Git verb for bringing changes from a remote repository to the local repository -
diffis a Git verb for viewing the difference between an edited file and the file’s most recent commit
Content from Review
Last updated on 2026-06-23 | Edit this page
Overview
Questions
- How can I cement my understanding of Git’s functions?
Objectives
- rephrase Git commands using everyday language
- demonstrate Git’s functions by drawing or sketching
Let’s review
It is likely that some things won’t have stuck from the last hour. To try to reinforce how things work we can work in groups to develop diagrams to illustrate Git functions and language. This should make carrying out more complicated aspects of Git clearer in our heads.
In groups:
- illustrate the concepts discussed in the first hour
- try to ‘draw’ what different commands mean
- try to come up with synonyms for what the commands are doing.
Exercise - visualising git
In group work, spend some time trying to illustrate some of the commands we’ve used with Git:
- try to express git commands in a non ‘git’ way
- try to visualise what commits are doing to your repository
If you want to practise more feel free to keep practicising making changes to your file and committing the changes. If you want to explore more git commands, search for some more online or follow one of the suggested links below.
Reflection
- Use your terminal to make file on your desktop (or another location
you prefer) titled
open-humanities-pt3.txt. - Add some notes about things you want to remember
- add reflections to the bottom of your file.
Some questions to consider: 1. When is a time you wish you had git? 1. How might you use git in your work? 1. What else do you want to learn about git and GitHub?
Feedback
Use your sticky notes to give the instructors feedback for today.
- On the “good” color, share one thing you liked about today or something you are glad you learned.
- On the “need help” color, share one thing you are still confused about or one thing that could have been better
- the language of Git can be confusing and intimidating
- rephrasing commands and drawing concepts can clarify Git’s workflow
Content from GitHub Pages
Last updated on 2026-06-23 | Edit this page
GitHub Pages
GitHub Pages is a simple service to publish a website directly on GitHub from a Git repository. You add some files and folders to a repository and GitHub Pages turns it into a website. You can use HTML directly if you like, but they also provide Jekyll, which renders Markdown into HTML and makes it really easy to setup a blog or a template-based website.
Enable GitHub Pages on the hello-world repo
Remember: GitHub Pages is turned off by default for all new repositories, and can be turned on in the settings menu for any repository. Let’s set up a new site by enabling GitHub Pages for our recently created project.
- On your GitHub view of the hello-world project, go to the settings from the top tab menu
- Find
Pageson the list on the left - Change where it says
Nonetomainunder `Deploy from a branch
View your site
Usually it’s available instantly, but it can take a few seconds and
in the worst case a few minutes if GitHub are very busy. On the main
code page of your repo, find the about section and edit it
to include the link to your webpage and try opeinging the link Share the
link on Eitherpad
Check the box that says
Use your GitHub Pages website
Clone your “my-website” locally and explore its content
Today we created a repo (project) locally (on our terminal) and then created an online duplicate of it, then we linked them to each other to be able to “push” and “pull” changes. Basically saving our work on a cloud.
Now, let’s do it the other way around. We created a project online on day 1 called my-website. Let’s now create a local copy of this project to ourselves to be able to make changes to that project locally.
Use this instructional page to read about how to do so
- On your terminal
cdinto a folder where you want to have the local copy of your repo - run the command
git clone <link_to_project> - Confirm this was successful with
ls - Check the contents of the newly added project folder using
cd,lsandcat
Add material to your webpage locally
Now that we’ve become more comfortable with the shell and using git on the shell.
We’re going to add the material we had prepared, add it to our webpage and view it.
Start by copying the file of your choosing or the contents of it into a new file in your local repo.
Challenge: Contributing to a page owned by someone else (slightly easier way)
To practice using Git, GitHub pages and Markdown we can contribute to a GitHub pages site. Pair up in groups of two (or more if needed) and do the exercises below together.
Go to https://github.com/some-librarian/hello-world, where “some-librarian” is the username of your exercise partner.
Click on “Fork” in the upper right part of the screen to create a copy of the repository on your account. Once you have a fork > of your partner’s repository, you can edit the files in your own fork directly.
Click the “index.md” file, then click the edit pencil icon:
Now is good chance to try some Markdown syntax. Try some of the examples at Mastering Markdown. You can preview how it will look before you commit changes.
Once you are ready to commit, enter a short commit message, select “Create a new branch for this commit and start a pull request” and press “Propose changes” to avoid commiting directly to the main branch.
You can now go to the repository on your account and click “New Pull Request” button, where you can select base branches repositories, review the changes and add an additional explanation before sending the pull request (this is especially useful if you make a single pull request for multiple commits).
Your partner should now see a pull request under the “Pull requests” tab and can accept (“Merge pull request”) the changes there. Try this.
This whole process of making a fork and a pull request might seem a bit cumbersome. Try to think of why it was needed? And why it’s called “pull request”?
Optional challenge: Contributing to a page owned by someone else (slightly more complicated way)
Instead of making edits on the GitHub website you can ‘clone’ the fork to your local machine and work there.
Challenge
Try following the rest of the steps in this guide under “Time to Submit Your First PR”.
(If you followed step 1 and 2 in the previous challenge, you already have a fork and you can skip the creation of a new fork. Start instead at the section titled “Cloning a fork.” You can submit multiple pull requests using the same fork.)
Content from What-is-myst
Last updated on 2026-06-23 | Edit this page
Overview
Questions
- How can we build an interactive webpage using Markdown files?
- How do we initialize myst?
- What does myst need to run?
- How do I view my work?
Objectives
- Explain what myst is and its benafits
- Run myst for the first time
- Check myst requirments
- View the webpage we built locally
Introduction
MyST is an open-source, community-driven project to improve scientific communication, including integrations into Jupyter Notebooks and computational results. (Sourced from mystmd.org’s Project goals)
Myst is a tool that we will learn to use to build interactive webpages or pdfs. The benifit of this is more powerful publishing of content and information. Here’s an example of a paper published using myst: A Literature Review On AI fairness Best Practices
A Different Way of Building HTML
The purpose of MyST is to have a powerful tool that builds
interactive HTML pages without doing any HTML coding. Remember, on the
first day we used GH Pages’ simple rendering system to render a single
md file (index.md) into a simple HTML page. MyST can also
do this, except that it uses templates to render pages with a more
structure, does some extra processing of the content and it can render a
collection of md files distributed across multiple directories within
one project directory into a cohesive site.
Let’s learn about using myst on the simple repo we created on the first day.
Starting myst
Open your terminal and cd into your
my-website repo’s directory Type the command
code into your terminal
Notice how you can access your terminal directly from vscode too!
In your terminal type myst:
Welcome to the MyST CLI! 🎉 🚀
myst init walks you through creating a myst.yml file.
You can use MyST to:
- create interactive websites from markdown and Jupyter Notebooks 📈
- build & export professional PDFs and Word documents 📄
Learn more about this CLI and MyST Markdown at: https://mystmd.org
✅ Project already initialized with config file: myst.yml
✅ Site already initialized with config file: myst.yml
? Would you like to run myst start now? Answer the prompt with yes
? Would you like to run myst start now? Yes📖 Built README.md in 62 ms.
📖 Built index.md in 364 ms.
📚 Built 2 pages for project in 482 ms.
✨✨✨ Starting Book Theme ✨✨✨
🔌 Server started on port 3000! 🥳 🎉
👉 http://localhost:3000 👈
╭────────────────────────────────────────────╮
│ │
│ Update available! v1.5.1 ≫ v1.6.0 │
│ │
│ Run `pip install -U mystmd` to update. │
│ │
│ Follow @mystmd.org for updates! │
│ https://bsky.app/profile/mystmd.org │
│ │
╰────────────────────────────────────────────╯This tells you that all the files that were in your directory (README.md & index.md) were built into a website locally.
Locally means this content is hosted on your machine. Not published for the public to be able to access.
To view this website follow the link provided in the prompt:
http://localhost:3000
If your port 3000 was already occupied you might get a
different number
What did this do?
Firstly we notice that the files in the directory got increased by 1. The new file is called myst.yml as mentioned by the output from the command we ran.
If we opened the webpage using the link above we see somthing like this


We notice a few things on this page:
- On the top-left corner says Made with Myst - For each md
file we have a button on the left page section - On the top-right corner
we have a dark/light theme button as well as a search bar that
works!
Edit your readme file and see what happens
We notice how myst tracks all requests on the local host and applies the changes made to the readme file immedietly to the webpage
OUTPUT
💌 GET /readme?_data=routes%2F%24 200 - - 9.687 ms
📖 Built README.md in 57 ms.
💌 GET /readme 200 - - 18.691 ms
What does that tell us?
We were able to create an interactive webpage using the same markdown
files and turn them into an interactive page. We used the
myst tool to make the webpage look nicer and have more
powers.
We also notice that with every change we make the contents of the
_build folder get rebuilt to generate the
newly updated material and settings. And we see a large number of files
in there that we might want to hide from the front face of our GitHub
repo.
What did myst need to run?
We noticed earlier that myst added a file to our directory as soon as
we ran it. myst.md Let’s figure out why it did so by
viewing the contents of it and trying to understand it.
or view it using vscode
YAML
# See docs at: https://mystmd.org/guide/frontmatter
version: 1
project:
id: 5f256b79-5f82-4a71-b061-138da64f191a
# title:
# description:
# keywords: []
# authors: []
github: https://github.com/mystudyroom0/my-website
# To autogenerate a Table of Contents, run "myst init --write-toc"
site:
template: book-theme
# options:
# favicon: favicon.ico
# logo: site_logo.pngWe find that the the file holds some metadata for the webpage. Most
of it isn’t filled in and is also commented out since it isn’t filled
out yet. (we comment lines in the YAML syntax using the #
symbol). We also some site settings such as the theme, logo and icon. So
we learn that myst requires this file to be in your project directory to
be able to built the webpage.
Editing meta data
Change the title of your webpage from the myst.yml file
and observe the difference before and after
Let’s look at how the tab is labeled on the browser and what the page title looks like


Edit the metadata of your webpage from myst.yml. Remove
the # to uncomment the line that has title: in
it and then add a title to your webpage.
YAML
# See docs at: https://mystmd.org/guide/frontmatter
version: 1
project:
id: b9be35e6-0f75-4da5-b971-9add4d00ed44
title: Benchmarking proposal
# description:
# keywords: []
# authors: []
github: https://github.com/some-humanist/my-website
# To autogenerate a Table of Contents, run "myst init --write-toc"
site:
template: book-theme
# options:
# favicon: favicon.ico
# logo: site_logo.png

- Myst is a tool that builds interactive webpages from markdown files
- To built a webpage using myst we simply start myst on the terminal
- Myst requires the file
myst.mdto run and build a webpage
Content from formatting-with-frontmatter
Last updated on 2026-06-23 | Edit this page
Overview
Questions
- How do you format your webpage using frontmatter?
- How do you have preview glossary in your webpage nicely?
- How do you change your webpage’s theme?
Objectives
- Explain what frontmatter is and how it’s used
- Experiment with having definitions and glossary viewed nicely on your webpage
- Demonstrate how to change the theme of a webpage
What is frontmatter
Frontmatter is a way to format your project. It is a section
separated by --- as delimeters that can be found in the
myst.md file or can be added individually at the top of any
md file to affect individual pages.
Frontmatter is one of the things that makes MyST special. Remember that we talked about how MyST is a tool that gives our project superpowers by giving it a more dynamic and interactive interface.
Frontmatter fields can be used in different scopes that can be divided into four: * Page & project * Page only * Page that can override project * Project only
Example frontmatter:
YAML
---
title: My First Article
date: 2022-05-11
authors:
- name: Smart Person
affiliations:
- University of Rhode Island
---We saw how we were able to change the title of our webpage from the
frontmatter found in the myst.md file.
How can we change the title of a section of the webpage using front matter?
Change the title of the paper added to the webpage
Change the title of the paper added last session to reflect on the webpage
If we add a header to the file using # myst recognizes
the larger header and names the section of the webpage according to it.
Try adding # to the first line of your text file witn a
meaningful name.
At the top of the file add the following
---
title: <Better_Title>
---We don’t need to re-build the webpage manually, myst automatically re-builds every time we save new changes to our webpage
MyST Themes
One of the main things that the configuration file can be used for is
to choose the main theme of the webpage. There are two themes offered by
myst: book-theme & article-theme
The one we saw in the example was using the
article-theme
Glossary
A gossary is a collection of definitions for the different terms that can be found of your website. Since your website is either a in a book style or an article style. There’s a large chance that it holds great scienfic information. Some of which might need to be well-defined for your target audience or the general public.
To add definitions to a glossary for our site what we need is mainly what myst considers a glossary body.
A glossary body has the following format:
:::{golssary}
<term>
: <definition>
<term>
: <definition>
...
:::A glossary body can be exist in any file in our project or, for organization purposes, can be on a file of its own.
Let’s start by creating a file called in our repo called
glossary.md
The second step is to pick a few words that might need to be defined in our paper/article and add them to our Glossary file wrapped in one glossary body.
The last step is to find the items we added to our glossary, surrounding it with backticks (`) and prefix it with {term}.
Remember to add, commit and push your changes to update the online repo
Accronyms
In any article, paper, or general text some words are repeated and sometimes it might be tedious to type the words everytime they need to be mentioned. So we use accronyms for those words.
To use accronyms in a file, we need to declare them in the
frontmatter header of the file with an object called
abbreviations and the list of words
Select some words in your paper and make them into acronyms or declare them as acronyms to myst
Select some words in your paper and make them into accronyms or declare them as accronyms to myst or use existing acronyms in the document
---
title: <Better_Title>
abbreviations:
<first>: Full words
<Second>: Full words
---Here is a list of frontmatter fields that can be used
Content from dynamic-content
Last updated on 2026-06-23 | Edit this page
Overview
Questions
- How do you cite papers with myst?
- What is the professional way to add figures to my webpage?
- How do you do cross referencing on your webpage?
Objectives
- Citing papers in markdown with myst
- Using relative paths to link figures
- Applying cross referencing on our webpage to have a nice and dynamic view
Introduction
How do we make our webpage more professional?
With dynamic links, nice looking figures and decent citing of papers and articals.
Adding figures
Adding figures to your webpage is essential to to make your webpage more descriptive. To do so, we add the figure/image file in the project directory. Then we link it in the page/md-file that we want it to show up in by adding its relative path using special md syntax.
The ![] tells markdown that there will be an image
linked next. Within parenthesis (()) we put a relative path
to an image from the location of the markdown file. As an optional
add-on we use curly brackets ({})
Citing papers
Including citations on your webpage is important. It provides the webpage with an extra layer of credibility to your contenr and provides the readers with access to the original sources and resources they might want to explore further.
To do so, we start by locating the bibtex of the
resource we want to cite. An easy way to do so is to look it up using google scholar, clicking on the
cite button at the bottom of the result and then select
BibTeX.
for example
@article{huang2023mlagentbench,
title={Mlagentbench: Evaluating language agents on machine learning experimentation},
author={Huang, Qian and Vora, Jian and Liang, Percy and Leskovec, Jure},
journal={arXiv preprint arXiv:2310.03302},
year={2023}
}The next step is to add the citing to a dedicated file in your
project named Bibliography.bib.
Finally, use the header of the citation with the @
symbol to have myst cite the article in a neat way!
For the example above, the paper can be cited in my content using
@huang2023mlagentbench
Create your own Bibliography
Find a citing that might be useful for your material and add it to
your own Bibliography.bib
touch Bibliography.bibcopy the citing and place it inside the file
Content from publishing-myst
Last updated on 2026-06-23 | Edit this page
Overview
Questions
- How do you utilize GitHub Pages to publish your myst webpage?
- How do you utiliza GitHub branches for publishing a webpage?
Objectives
- Explain how to use GitHub Pages to dyploy a webpage built with myst
- Use GitHub branches to hold the webpage data and not clutter the repo
Publishing your myst webpage
Now to finally see our nice work published!
We’re going to use GitHub Pages again, similar to what we did in day one.
But wait, we added the _build folder to
.gitignore to prevent git from tracking this information
and requiring git add, git commit and
git push for those changes.
Why don’t we want to track these changes?
The first reason is that they’re a lot of files and they will clutter the GitHub repository. Not to mention that tracking all of the changes in terms of adding and committing might get annoying and tricky.
The second reason is that all these files are generated from the content of our md files. Along with all the necessary files that represent all the settings from frontmatter, the nice formatting tricks, citing and crossreferencing. Think of how we made small changes to our project and we could see the changes apply immediately or within a few seconds. Similar to how myst was able to build the website on our local machine, we can have myst run on a cloud-hosted platform provided by GitHub.
This is done on a branch separate from main.
What are branches?
Branches are like copies of the project that can hold independant changes to the project in them. They are used to make individual fixes/changes. This is beneficial first and foremost so that we don’t make changes directly on the main branch because the main branch holds the contents that are published to the public or on software development main holds the code that is release-ready for use. Branches also help with collaboration aspects where two people can work on different tasks making different changes on two different branches.
Nice of myst, myst provides its users to use GitHub Actions and
branches to run myst on the GitHub-based cloud, generate the
_build folder with the interactive webpage that can be
published.
To do so on our terminal we will run the command
myst init --gh-pages.
Then follow the steps as instructed by myst.
Do this yourself!
Run myst init --gh-pages for your project and follow the
steps to be able to publish your project using GitHub Pages
- Branches are used to keep the main branch safe and for collaboration
- GitHub Pages can publish myst-built webpages if directed to the HTML file
- Myst provides us with an easy way to use GH Pages
Content from closing-next-steps
Last updated on 2026-06-23 | Edit this page
Overview
Questions
- What comes next?
Objectives
- Provide information on next steps locally
- Reflect & Review
- Answer final questions
- Collect Feedback
This lesson is open source
You can help us improve this over time! Issues are valuabe too, not only PRs.
Local Resources
Most universities core open research practices are concentrated in two places: - libraries (sometimes with an emphasis on no-paywall rather than open source) - research computing (sometimes with an emphasis on scientific computing)
Closing
Reflection
On paper, or your favorite drawing tool, visualize what we have learned.
Call to Action
Consider how you can maximize the time you spent learning in this workshop. It’s okay to dream big, but momentum builds from small wins, so we challenge you to think of at least one small thing that you are very confident you can do.
Some ideas: - Set one realistic goal of how you will use what you learned in your scholarship or teaching in the next two weeks, set yourself a reminder (or calendar invite) - Send an email/ schedule a meeting with one person you met who you want to stay in touch with - Set aside some time to review one particular point or explore one new idea you have based on the workshop
Community building
What would you want to continue building?
One up, One down
Provide one up, one down feedback on the entire workshop. Rules:
- Say only one thing, and try not to duplicate. This gets harder for those who come later!
- Instructors will try not to respond, only record responses (e.g. in the Etherpad). This is also hard, but important!
This exercise should take about 15 minutes.
Anonymous Feedback
Use your sticky notes to give the instructors feedback for today.
- On the “good” color, share one thing you liked about today or something you are glad you learned.
- On the “need help” color, share one thing you are still confused about or one thing that could have been better
- Open research is possible and beneficial to all disciplines
- Computational literacy helps you automate tasks
- git keeps track of different versions of your work; any sort of text, not only code
- myst builds websites (HTML and js) from markdown